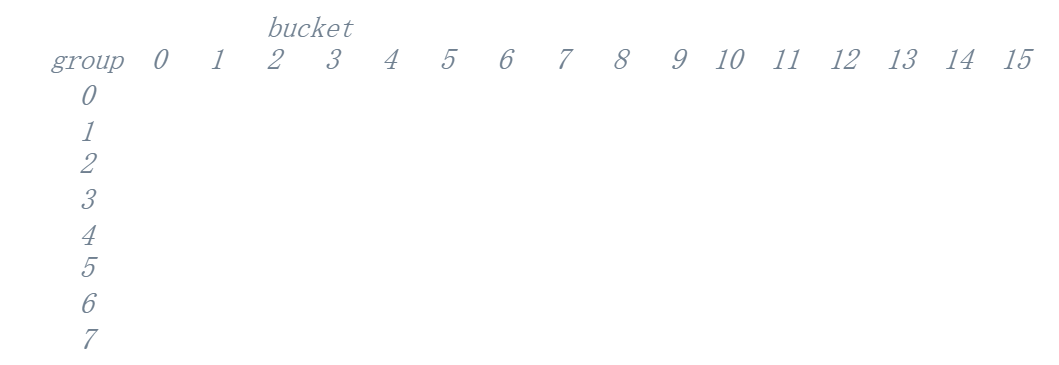/* Create an initial clone of matching data for next insertion */ priv->clone = pipapo_clone(m); if (IS_ERR(priv->clone)) { err = PTR_ERR(priv->clone); goto out_free; }
if (nft_set_ext_exists(ext, NFT_SET_EXT_KEY_END)) end = (const u8 *)nft_set_ext_key_end(ext)->data; else end = start;
dup = pipapo_get(net, set, start, genmask); if (!IS_ERR(dup)) { /* Check if we already have the same exact entry */ conststructnft_data *dup_key, *dup_end;
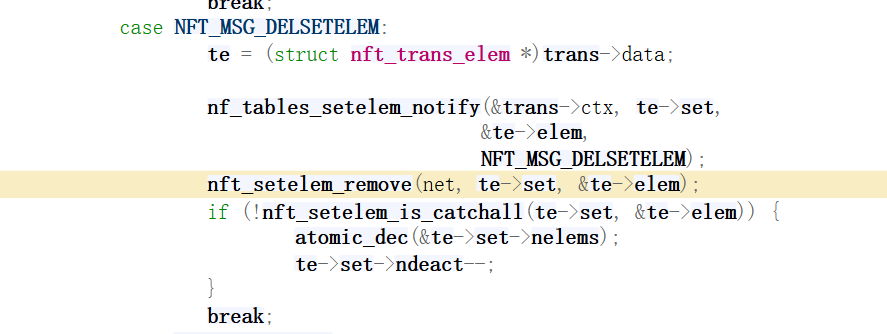
staticintpipapo_insert(struct nft_pipapo_field *f, constuint8_t *k, int mask_bits) { int rule = f->rules++, group, ret, bit_offset = 0;
ret = pipapo_resize(f, f->rules - 1, f->rules); if (ret) return ret;
for (group = 0; group < f->groups; group++) { int i, v; u8 mask;
v = k[group / (BITS_PER_BYTE / f->bb)]; v &= GENMASK(BITS_PER_BYTE - bit_offset - 1, 0); v >>= (BITS_PER_BYTE - bit_offset) - f->bb;
bit_offset += f->bb; bit_offset %= BITS_PER_BYTE;
if (mask_bits >= (group + 1) * f->bb) { /* Not masked */ pipapo_bucket_set(f, rule, group, v); } elseif (mask_bits <= group * f->bb) { /* Completely masked */ for (i = 0; i < NFT_PIPAPO_BUCKETS(f->bb); i++) pipapo_bucket_set(f, rule, group, i); } else { /* The mask limit falls on this group */ mask = GENMASK(f->bb - 1, 0); mask >>= mask_bits - group * f->bb; for (i = 0; i < NFT_PIPAPO_BUCKETS(f->bb); i++) { if ((i & ~mask) == (v & ~mask)) pipapo_bucket_set(f, rule, group, i); } } }
pipapo_lt_bits_adjust(f);
return1; }
pipapo_map:
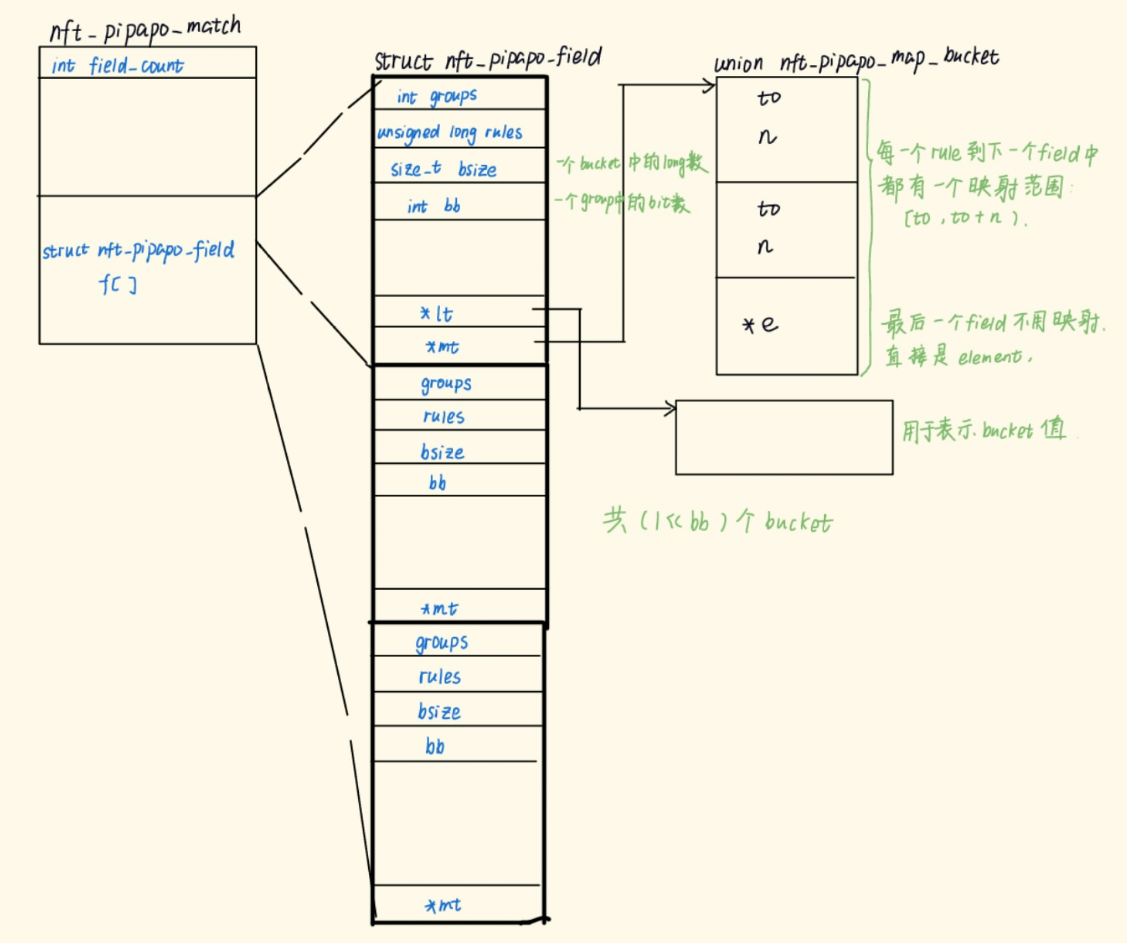
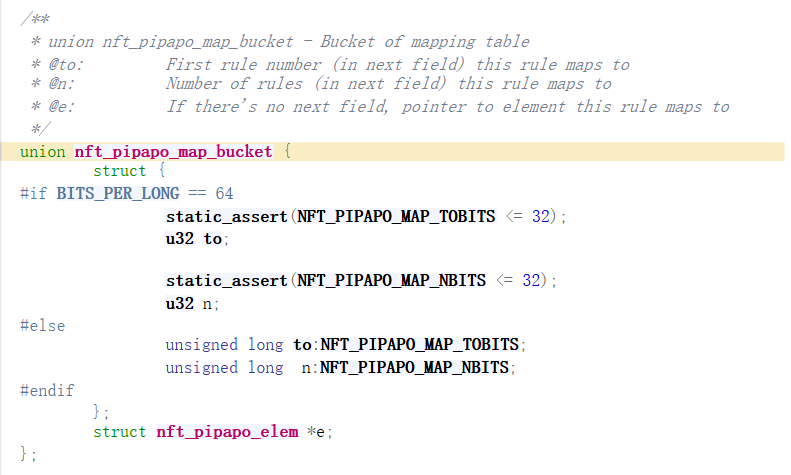
/** * pipapo_map() - Insert rules in mapping tables, mapping them between fields * @m: Matching data, including mapping table * @map: Table of rule maps: array of first rule and amount of rules * in next field a given rule maps to, for each field * @e: For last field, nft_set_ext pointer matching rules map to */ staticvoidpipapo_map(struct nft_pipapo_match *m, union nft_pipapo_map_bucket map[NFT_PIPAPO_MAX_FIELDS], struct nft_pipapo_elem *e) { structnft_pipapo_field *f; int i, j;
for (i = 0, f = m->f; i < m->field_count - 1; i++, f++) { //遍历每一个域,除了最后一个 for (j = 0; j < map[i].n; j++) { //在域i中映射了map[i].n个rule f->mt[map[i].to + j].to = map[i + 1].to;//map[i].to是起始rule的idx f->mt[map[i].to + j].n = map[i + 1].n; } }
/* Last field: map to ext instead of mapping to next field */ for (j = 0; j < map[i].n; j++) f->mt[map[i].to + j].e = e; //最后一个直接写入元素的地址,这也就是element挂入的位置 }
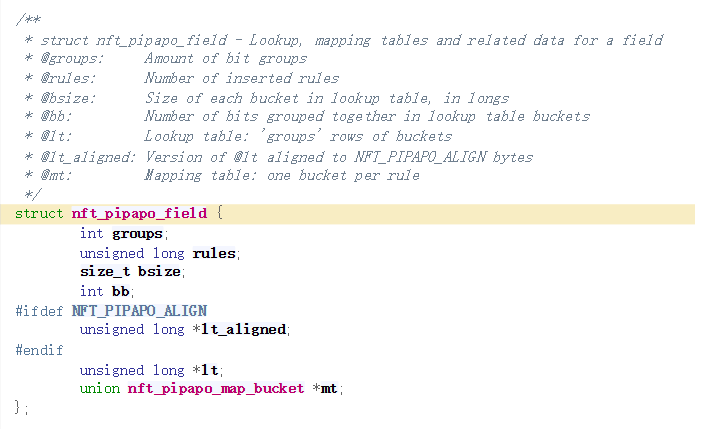
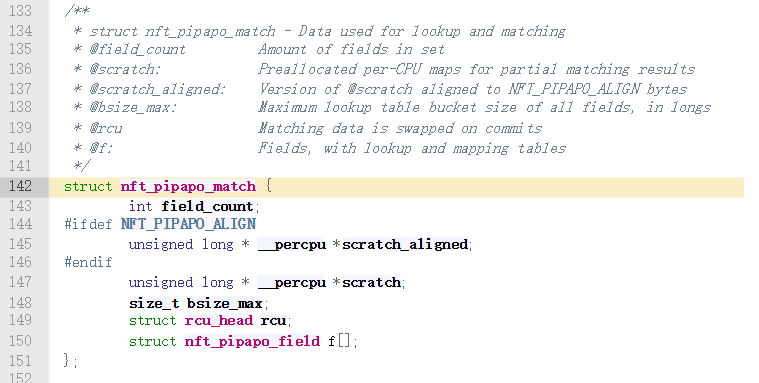
/** * pipapo_resize() - Resize lookup or mapping table, or both * @f: Field containing lookup and mapping tables * @old_rules: Previous amount of rules in field * @rules: New amount of rules * * Increase, decrease or maintain tables size depending on new amount of rules, * and copy data over. In case the new size is smaller, throw away data for * highest-numbered rules. * * Return: 0 on success, -ENOMEM on allocation failure. */ staticintpipapo_resize(struct nft_pipapo_field *f, int old_rules, int rules) { long *new_lt = NULL, *new_p, *old_lt = f->lt, *old_p; unionnft_pipapo_map_bucket *new_mt, *old_mt = f->mt; size_t new_bucket_size, copy; int group, bucket; //计算每个bucket需要的long的数量 new_bucket_size = DIV_ROUND_UP(rules, BITS_PER_LONG); #ifdef NFT_PIPAPO_ALIGN new_bucket_size = roundup(new_bucket_size, NFT_PIPAPO_ALIGN / sizeof(*new_lt)); #endif
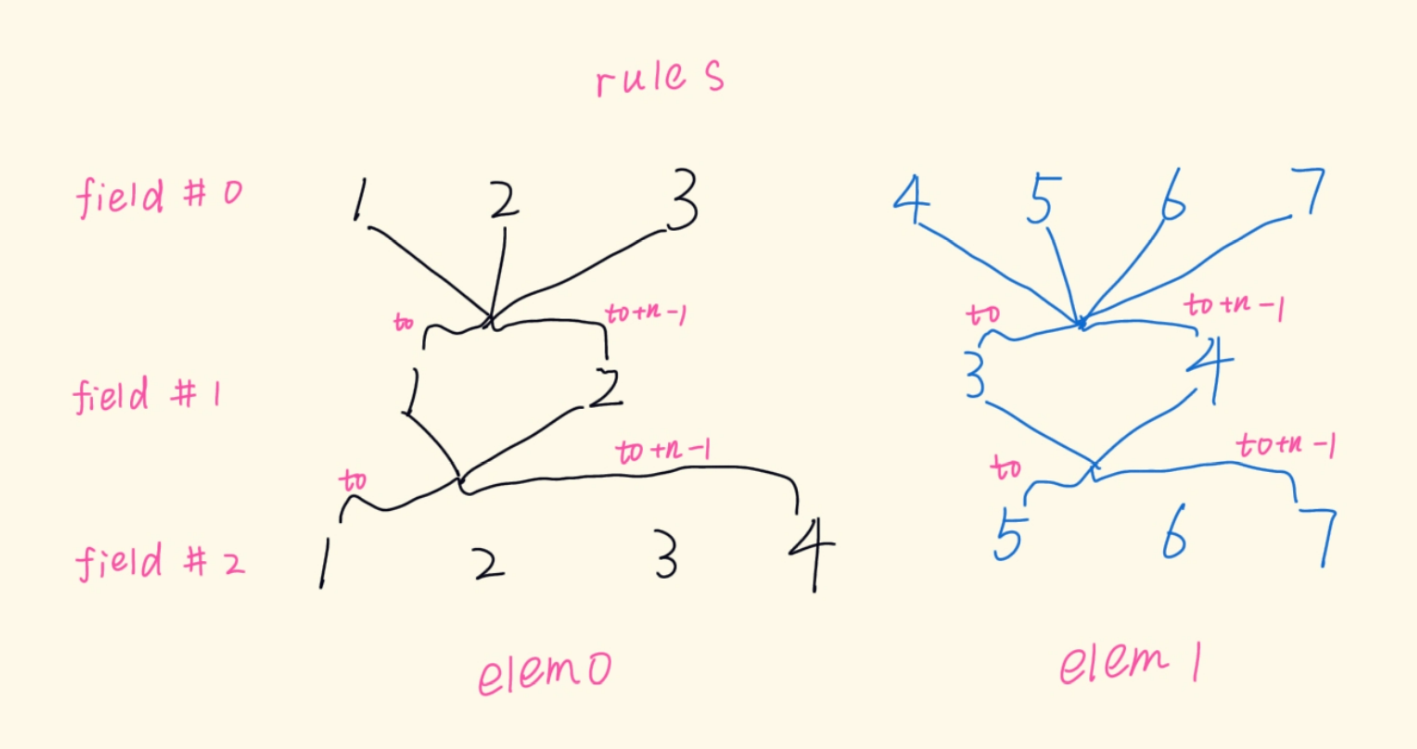
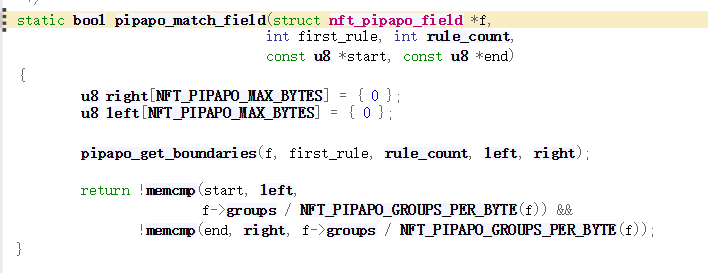
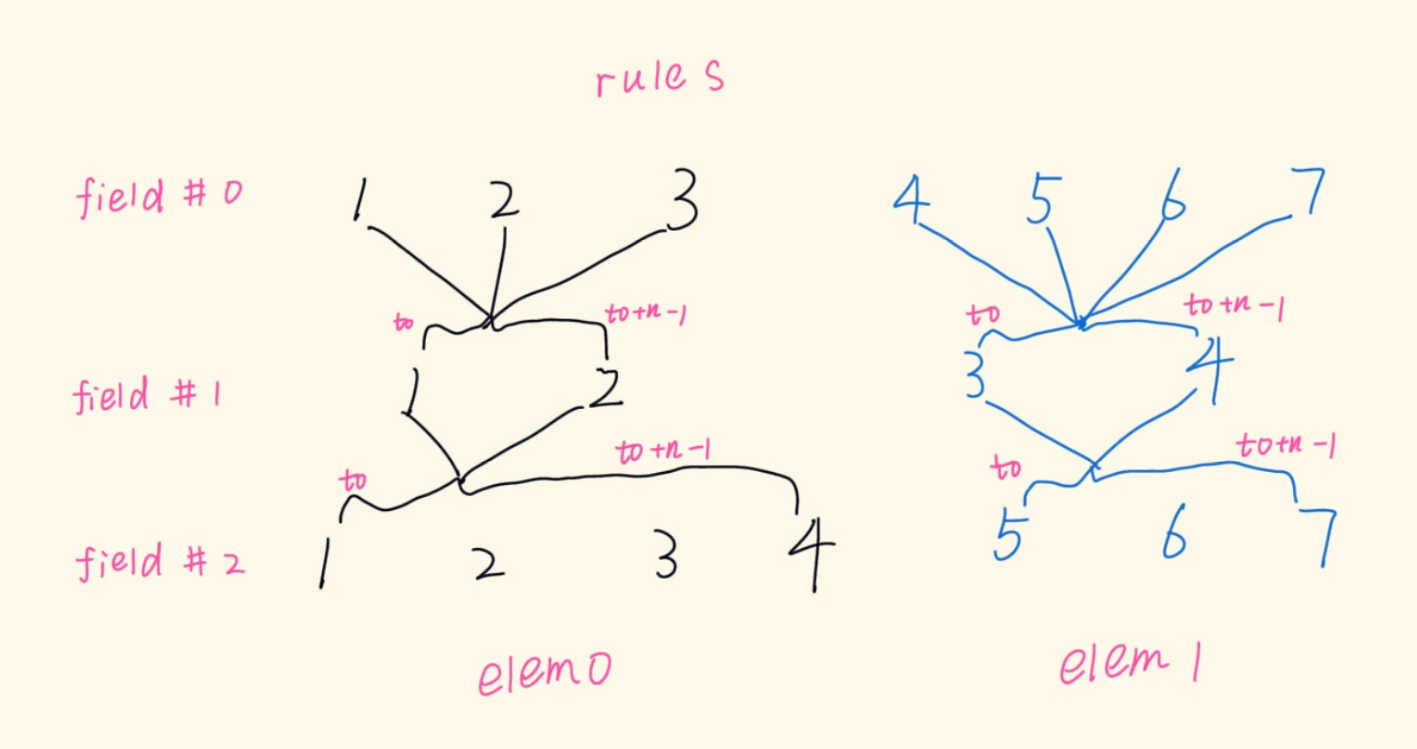
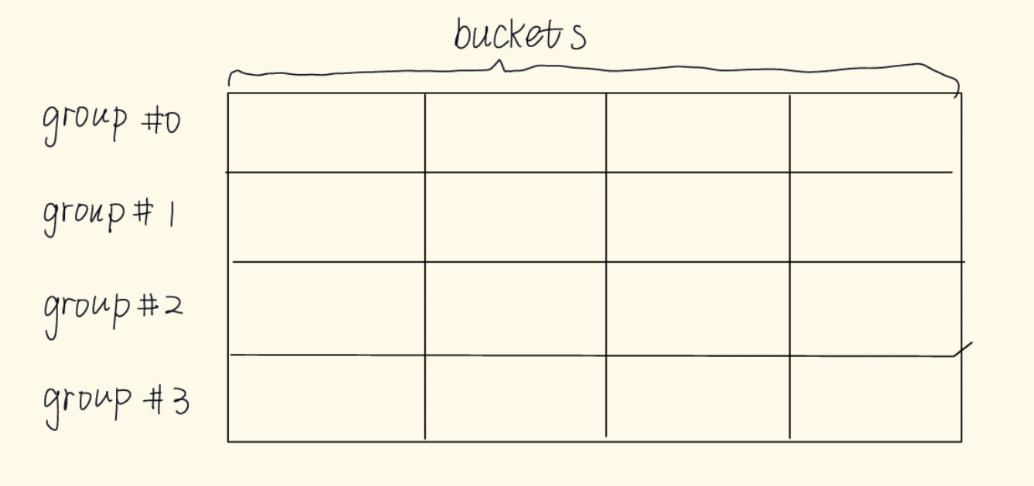
/** * pipapo_get_boundaries() - Get byte interval for associated rules * @f: Field including lookup table * @first_rule: First rule (lowest index) * @rule_count: Number of associated rules * @left: Byte expression for left boundary (start of range) * @right: Byte expression for right boundary (end of range) * * Given the first rule and amount of rules that originated from the same entry, * build the original range associated with the entry, and calculate the length * of the originating netmask. * * In pictures: * * bucket * group 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 * 0 1,2 * 1 1,2 * 2 1,2 * 3 1,2 * 4 1,2 * 5 1 2 * 6 1,2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 * 7 1,2 1,2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 * * this is the lookup table corresponding to the IPv4 range * 192.168.1.0-192.168.2.1, which was expanded to the two composing netmasks, * rule #1: 192.168.1.0/24, and rule #2: 192.168.2.0/31. * * This function fills @left and @right with the byte values of the leftmost * and rightmost bucket indices for the lowest and highest rule indices, * respectively. If @first_rule is 1 and @rule_count is 2, we obtain, in * nibbles: * left: < 12, 0, 10, 8, 0, 1, 0, 0 > * right: < 12, 0, 10, 8, 0, 2, 2, 1 > * corresponding to bytes: * left: < 192, 168, 1, 0 > * right: < 192, 168, 2, 1 > * with mask length irrelevant here, unused on return, as the range is already * defined by its start and end points. The mask length is relevant for a single * ranged entry instead: if @first_rule is 1 and @rule_count is 1, we ignore * rule 2 above: @left becomes < 192, 168, 1, 0 >, @right becomes * < 192, 168, 1, 255 >, and the mask length, calculated from the distances * between leftmost and rightmost bucket indices for each group, would be 24. * * Return: mask length, in bits. */ staticintpipapo_get_boundaries(struct nft_pipapo_field *f, int first_rule, int rule_count, u8 *left, u8 *right) { int g, mask_len = 0, bit_offset = 0; u8 *l = left, *r = right;
for (g = 0; g < f->groups; g++) { //遍历一个field中的所有group int b, x0, x1;
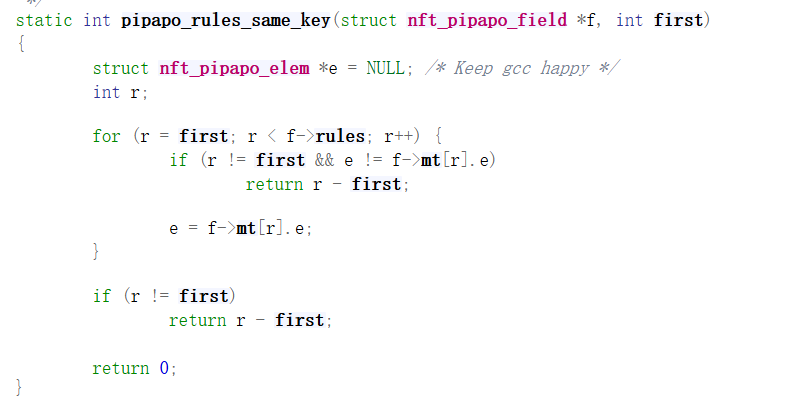
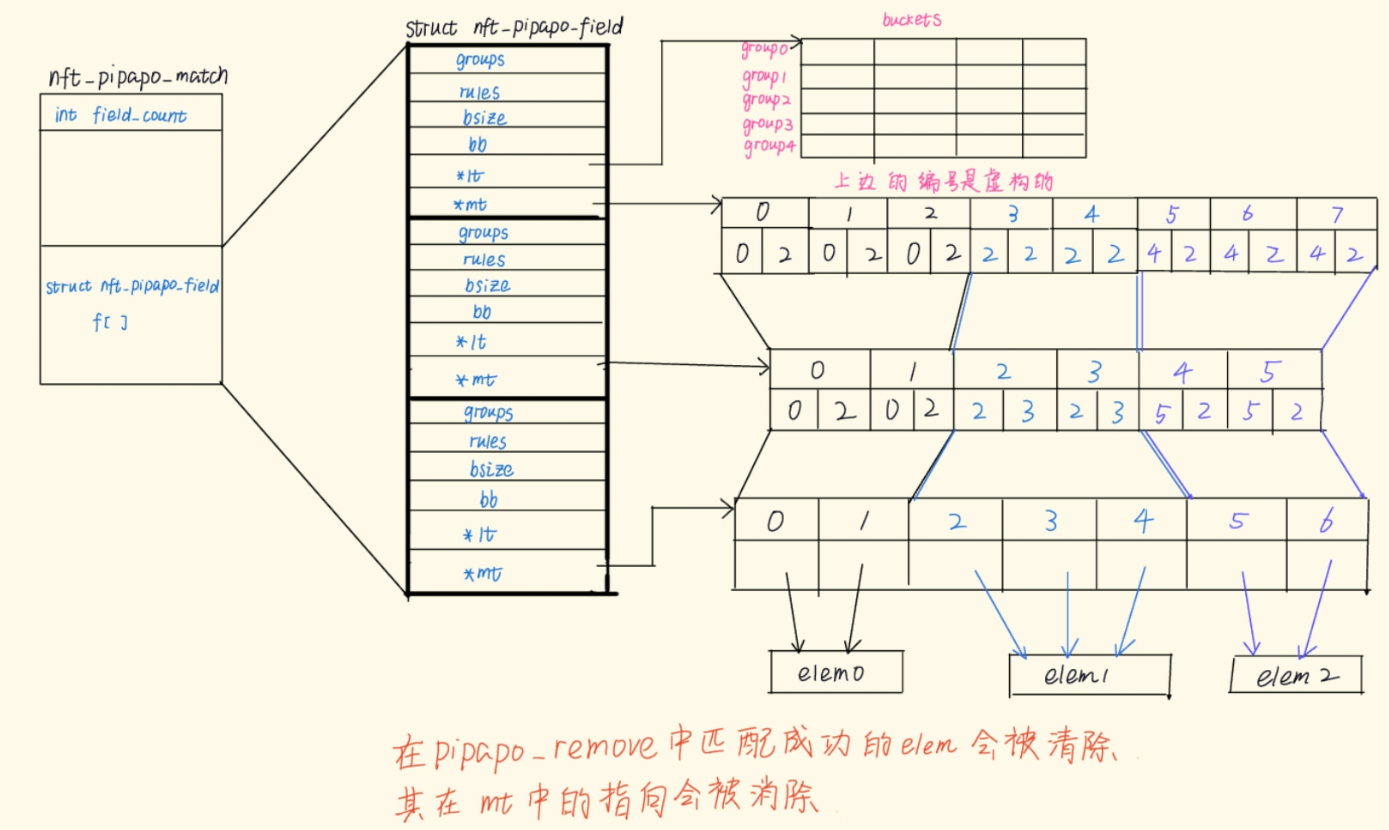
一个elem相当于一个[ip][port][ip]这种复合东西的形式化表示,我们要想删除这个elem就要保证每一个部分(域)的范围都对上了,nft_pipapo_for_each_field(f, i, m)这个循环就是要保证所有的部分(域)都匹配成功,而具体到pipapo_match_field函数中就是检查一个域,一个域又拆成好多group查各自的范围,完全匹配了才能说这个elem匹配成功了,就到下边调用pipapo_drop函数来删除elem;
pipapo_drop
pipapo_drop:
staticvoidpipapo_drop(struct nft_pipapo_match *m, union nft_pipapo_map_bucket rulemap[]) { structnft_pipapo_field *f; int i;
nft_pipapo_for_each_field(f, i, m) { int g;
for (g = 0; g < f->groups; g++) { unsignedlong *pos; int b; //bsize表示一个bucket中的long的数 //NFT_PIPAPO_BUCKETS(f->bb) * f->bsize 表示一个group中所有bucket占用的long的数 //pos指向当前group在lt中的起始位置 pos = NFT_PIPAPO_LT_ALIGN(f->lt) + g * NFT_PIPAPO_BUCKETS(f->bb) * f->bsize; // for (b = 0; b < NFT_PIPAPO_BUCKETS(f->bb); b++) { //迭代2^t次,每一个bucket一次 //bitmap_cut的作用大致就是处理一个bucket对应的lt空间 //从to位置开始n个bit给删除掉 bitmap_cut(pos, pos, rulemap[i].to, rulemap[i].n, f->bsize * BITS_PER_LONG); //f->bsize * BITS_PER_LONG 表示一个bucket占用的bit数,一般一个bit就是一个rule,但是要向上取整
pos += f->bsize; //下一个group的lt } }
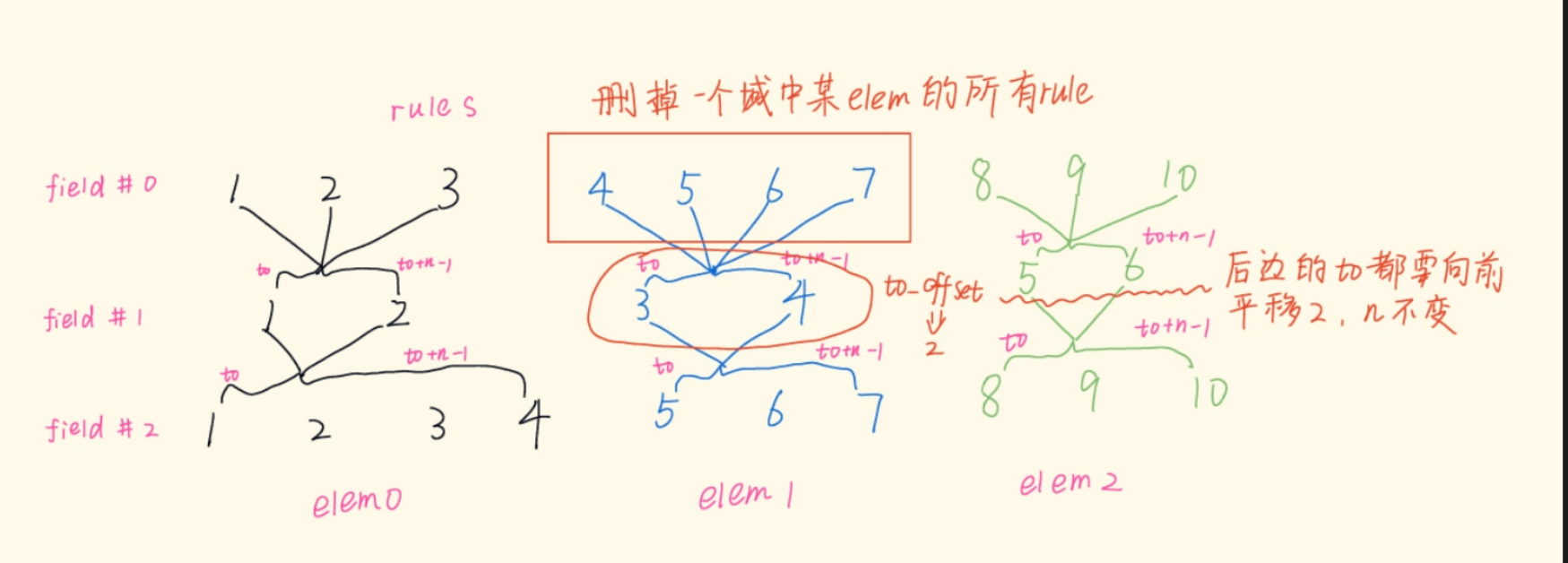
pipapo_unmap(f->mt, f->rules, rulemap[i].to, rulemap[i].n, rulemap[i + 1].n, i == m->field_count - 1); if (pipapo_resize(f, f->rules, f->rules - rulemap[i].n)) { /* We can ignore this, a failure to shrink tables down * doesn't make tables invalid. */ ; } f->rules -= rulemap[i].n;
staticvoidpipapo_unmap(union nft_pipapo_map_bucket *mt, int rules, int start, int n, int to_offset, bool is_last) { //mt is f->mt, rules is f->rules //start: rule_start, n is count //to_offset : 下一个field中的映射个数 //is_last: 标识本field是不是最后一个field int i; //将start ~ start+n-1 的空间覆盖掉,后边腾出来的空间清零 memmove(mt + start, mt + start + n, (rules - start - n) * sizeof(*mt)); memset(mt + rules - n, 0, n * sizeof(*mt)); // if (is_last) return; //从start开始都要改变映射关系 for (i = start; i < rules - n; i++) mt[i].to -= to_offset; }
/** * pipapo_commit() - Replace lookup data with current working copy * @set: nftables API set representation * * While at it, check if we should perform garbage collection on the working * copy before committing it for lookup, and don't replace the table if the * working copy doesn't have pending changes. * * We also need to create a new working copy for subsequent insertions and * deletions. */ staticvoidpipapo_commit(conststruct nft_set *set) { structnft_pipapo *priv = nft_set_priv(set); structnft_pipapo_match *new_clone, *old;
if (time_after_eq(jiffies, priv->last_gc + nft_set_gc_interval(set))) pipapo_gc(set, priv->clone);
if (!priv->dirty) return;
new_clone = pipapo_clone(priv->clone); if (IS_ERR(new_clone)) return;
priv->dirty = false;
old = rcu_access_pointer(priv->match); rcu_assign_pointer(priv->match, priv->clone); if (old) call_rcu(&old->rcu, pipapo_reclaim_match);
priv->clone = new_clone; }
/** * pipapo_reclaim_match - RCU callback to free fields from old matching data * @rcu: RCU head */ staticvoidpipapo_reclaim_match(struct rcu_head *rcu) { structnft_pipapo_match *m; int i;
m = container_of(rcu, struct nft_pipapo_match, rcu);