paper: https://jiongyichen.github.io/pubs/NDSS_23.pdf
NDSS-2023
overview
目标:对普通用户态程序实现精确的堆风水;
步骤:
- 识别对操作原语,利用对操作依赖图,分析原语之间的依赖和能力;
- 将堆布局操作建模为一个整数线性规划问题,并解决了这些约束条件;
考虑到的问题:
- 原语之间的相互制约;
- 一个原语可能有多个堆操作;
- 堆机制存在类似于合并、切割这样的副作用;
Thread Model:
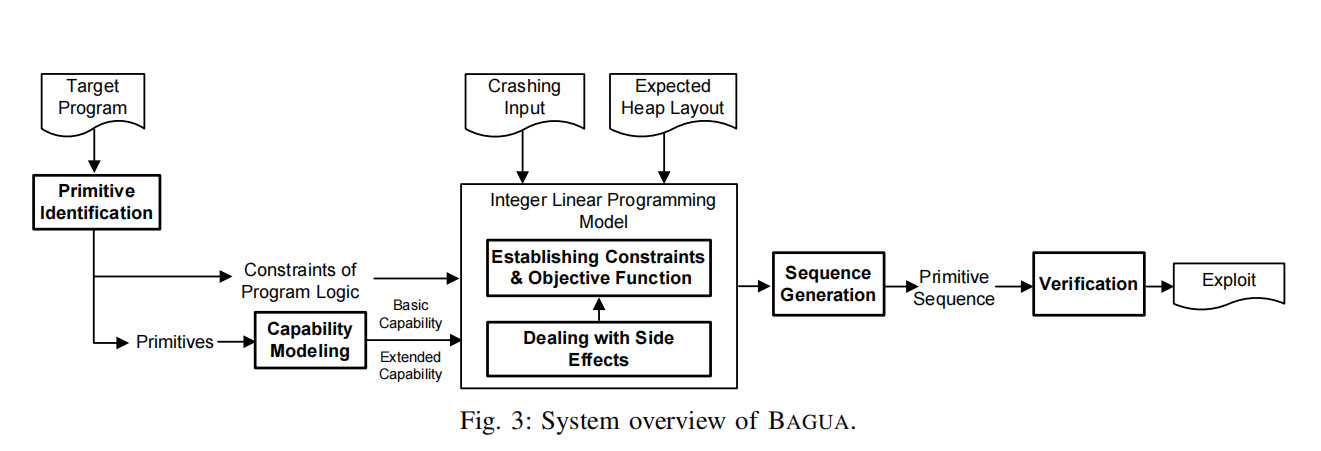
- 目标程序、crash input、预期布局;
- OOB-write、UAF;
- 输出原语序列;

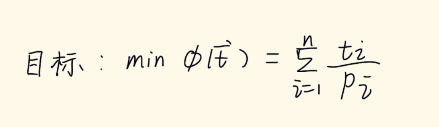
system design
- 利用堆操作指引的fuzz来识别各种堆操作,并决定调用次数;
- 提取分配操作的参数,通过数据流分析得到free的指针;
- 通过控制流分析得到原语之间的happen-before关系;
- 能力建模是在目标链上(应该指的是程序执行路径)dig和fill的洞的数量;
- 求解方程;
A.原语识别
构建HODG
用于刻画堆操作之间的数据流和控制流关系;
堆操作作为节点、控制流和数据流作为边;
利用堆操作引导的fuzz,hook点,比较set,加seed,等等;
之后决定哪一个指针被free,使用执行跟踪;(类似于动态回放?)
然后使用符号执行恢复malloc等分配函数的size参数;
最后提取数据流和控制流关系构建HODG:
还是依赖于大循坏这类结构,因此要先识别这类控制流;
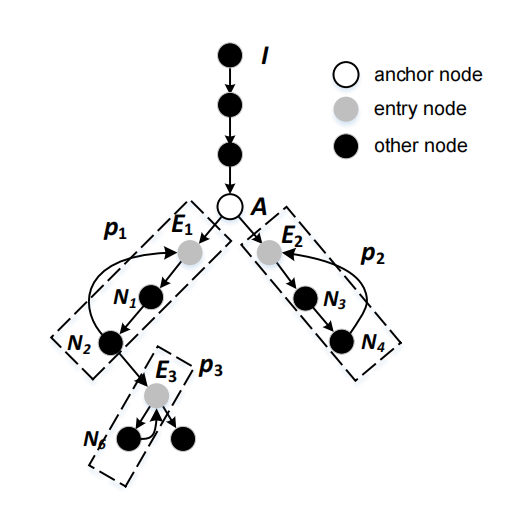
- 节点是堆操作,边是数据流和控制流;
- anchor node:第一个具有多个继承者的调度程序,通常为目标程序的事件调度程序。
- entry node:anchor node的后继节点都是entry node;
- 找到entry node之后,一个原语包括从entry node开始知道return到其他entry node之间的所有node;
Happen-Before Relationship
首先为HODG中所有基本元素的entry node构建一个支配树;
通过在支配树中定位其entry node的父节点,可以简单地实现原始语句之间的happen-before relationship;
看图中的p1和p3;
Number of Primitive Invocations
主要是为了防止程序逻辑中对某些操作的调用次数有限制,比如打CTF的时候经常会限制free的次数;
在每次运行中,我们记录每个基本操作的调用次数;
基于长期fuzz的大量执行,得到调用次数的最大值和最小值;
B.能力建模
堆操作的能力
挖洞+1,填洞-1;
基础能力
基础能力是没开合并切割机制的状态,此时的能力是确定性的,用c表示;
个人理解的是,最开始的分配肯定还是要从top_chun切割的,切完了可就合不回去了,也不能再细分了,这其实合内核有点像了,size固定了;
此时对于一个size为y的chain(应该就是tcache bin的链这样的一个东西),基础能力定义如下:
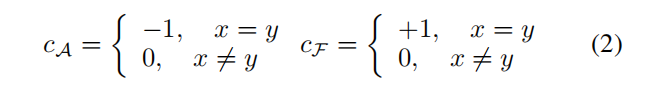
扩展能力
如果要分配x大小的chunk,但是chain_x的obj个数是0,但是chain_z(z==x+y)有obj,就会在chain_y上挖一个洞,同时会在z上填一个洞:
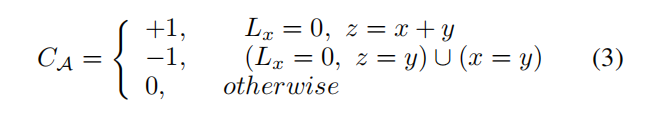
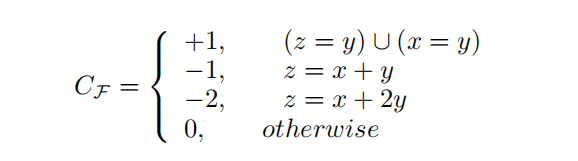
原语能力
C.线性整数规划方程
程序执行逻辑
数量限制就是求解的时候对目标加个约束;
先后顺序这里没说(
占据目标洞

D.处理副作用
- 加约束条件导致结果数量骤减;
- 方法一无解就用方法二,方法二会有错误解;
- 认证方法二的结果;
方法一
分析副作用的根本原因,将消除副作用变成一个新的挖掘和填坑的问题。


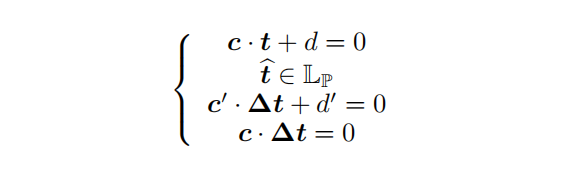
消除副作用的程序可能会带来新的副作用,因此,消除副作用是一个迭代过程,直到dig或fill不再产生新的副作用:
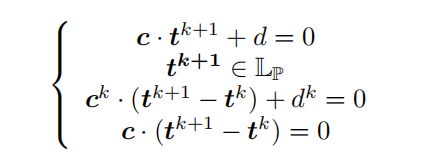
- k是迭代的次数;
- c = (c1, c2, …, cn)是每一个原语的基本能力(应该是在最开始目标chain上的)
- d是目标数目;
- $t^{k+1} = (t_1^{k+1}, t_2^{k+1}, …, t_n^{k+1})$并表示每一轮中原语选择的数量;(这里轮与轮之间的先后顺序是否 可以直接确定呢?🤔)
- ck代表每轮处理副作用的时候的能力呗;
- dk每轮的目标呗;
- Lp是数量限制;
在论文第7页右下角中原文描述如下:

这里对于free的副作用有个问题,如何知道是不是会导致合并?论文中并没有关于空间上的建模,🤔
方法二是
- 新加的约束条件导致无解;
- 有的情况是必须要切割chunk才能实现目标;
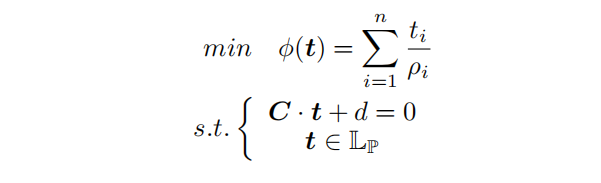
$C = (C_1, C_2, …, C_n)$代表扩展的能力,

E.多目标
多obj进入多洞
拆解成多个步骤,需要注意的是后边的free操作不要把前面已经实现占位的目标obj给释放了;
多obj进入一个大洞

F.原语排序与认证
Primitive Sorting
使用能力波动率,它表示序列中基本能力与平均值的偏差;
测量序列的质量并选择合适的序列;
优先考虑波动较小的序列,更不可能错误地占据目标孔并超过目标链的容量;


一个原语对应多个堆操作,每个堆操作也可以有一个能力值,这里没有合并到原语中;
在第一个函数中,So用于累加所有原语的所有能力,Rpi则只积累本原语执行过程中的So的求和,相当于一个sum的sum?🤔;
如果Rpi小于0说明是fill,就
Verification
根据目标原语序列,用fuzz去生成对应的输入,绕不过去就符号执行,甚至要人工参与推测一个字节;
关键是这个是用上边的启发式算法逐个试吗?😓😓



