节点
基本知识
关于为什么要有节点这个东西:https://www.cnblogs.com/linhaostudy/p/9992639.html#_label0_0
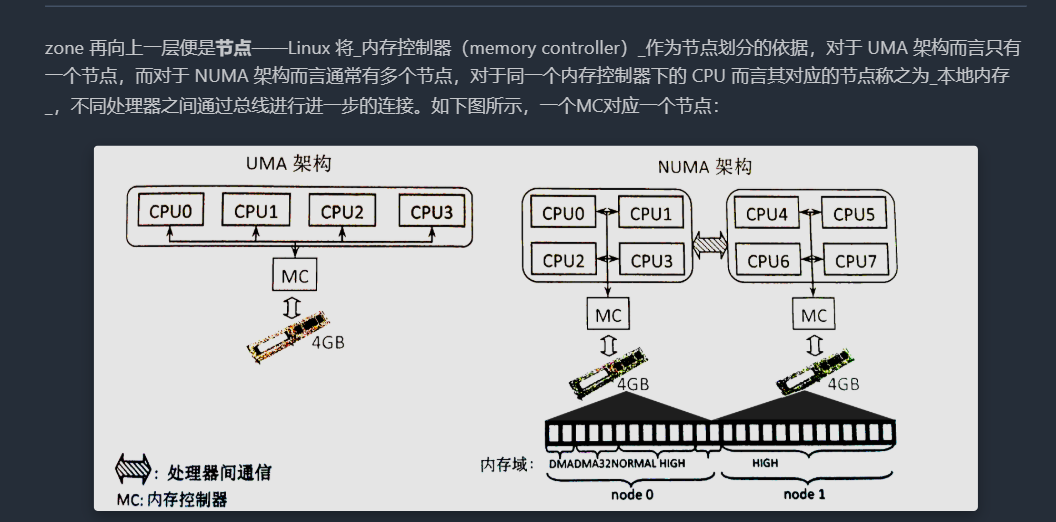
NUMA结构下, 每个处理器CPU与一个本地内存直接相连, 而不同处理器之前则通过总线进行进一步的连接, 因此相对于任何一个CPU访问本地内存的速度比访问远程内存的速度要快
Linux适用于各种不同的体系结构, 而不同体系结构在内存管理方面的差别很大. 因此linux内核需要用一种体系结构无关的方式来表示内存.
因此linux内核把物理内存按照CPU节点划分为不同的node, 每个node作为某个cpu结点的本地内存, 而作为其他CPU节点的远程内存, 而UMA结构下, 则任务系统中只存在一个内存node, 这样对于UMA结构来说, 内核把内存当成只有一个内存node节点的伪NUMA
因此,笔者个人的理解就是,当插入多个内存条之后,这些内存条可能架构不太一样,Linux要对它们进行统一的管理,因此就要在上层有一个node这种结构实现这个任务。
数据结构
一个节点使用 pglist_data 结构进行描述,该结构定义于 /include/linux/mmzone.h 中;
node_zones:node 的 zone 列表
node_zonelists:内存分配时备用 zone 的搜索顺序
nr_zones:node 中 zone 的数量
node_start_pfn:node 的起始页框标号
unsigned long node_spanned_pages: node 中物理页的总大小
node_id:node 的标号
node 存储方式:全局数组 node_data[],定义在/arch/x86/mm/numa.c;
node 状态:全局数组 node_states[],定义在 /mm/page_alloc.c,用以标识对应标号的节点的状态;
区
摘自@arttnba3
在 Linux 下将一个节点内不同用途的内存区域划分为不同的 区(zone),对应结构体 struct zone,该结构体定义于 /include/linux/mmzone.h 中;
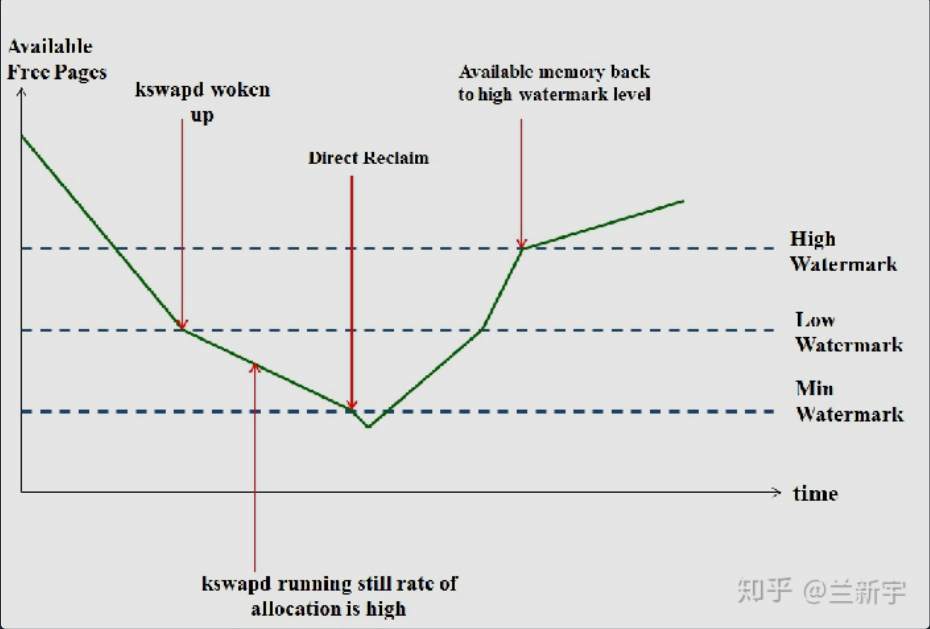
每一个 zone 都有着其对应的三档“水位线”: WMARK_MIN、WMARK_LOW、WMARK_HIGH,存放在 _watermark 数组中,在进行内存分配时,分配器(例如 buddy system)会根据当前 zone 中空余内存所处在的“水位线”来判断当前的内存状况,如下图所示:
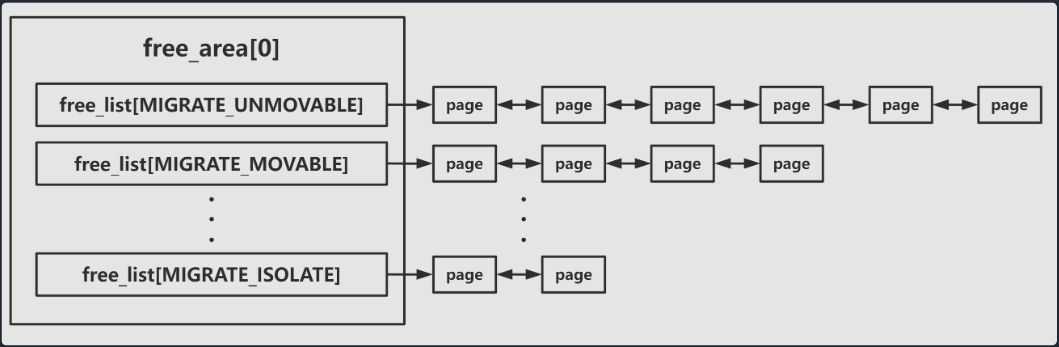
后边感觉知道per_cpu_pageset、free_area、以及迁移类型这三个知识就够了。
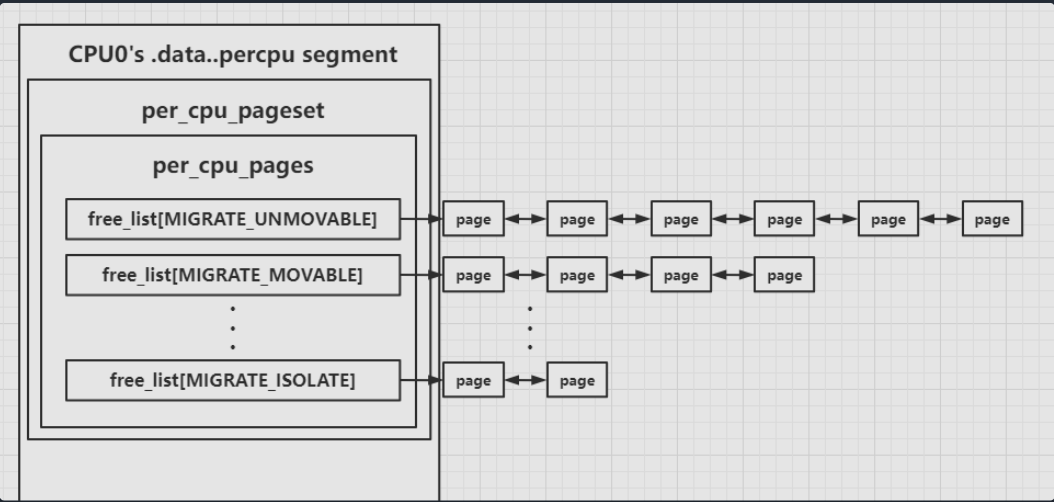
per_cpu_pageset就是对于order-0的页面分配(这是最频繁的)每一个CPU都有一个自己的私有页面集,(这种频繁的分配要尽量减少为避免竞争加锁导致的开销):
free_area用的就是buddy system算法进行分配:
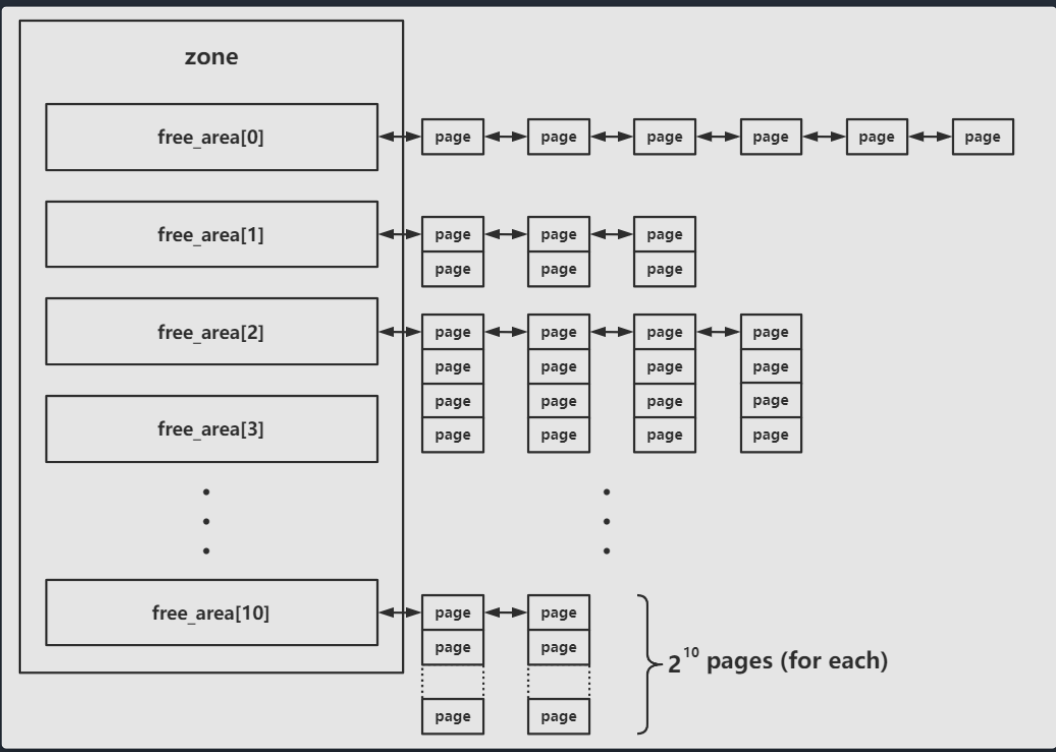
同时要注意的是,由于不同迁移类型的存在,每一个free_area会有多个链表:
OK!有了这些就可以去学buddy system了!😊😊
参考
https://www.cnblogs.com/linhaostudy/p/9992639.html#_label0_0



![buddy-system [half]](/medias/featureimages/7.jpg)