paper: https://www.usenix.org/system/files/sec20-chen-weiteng.pdf
摘要
提炼OOB漏洞的能力;
- 能力(capability)作为引导的fuzz;
- 组合这些capabilities去提升利用成功率;
内核exploit是多次交互的,各模块之间相对独立;
OOB漏洞的定义依据:
- 能越界写多远;
- 能越界写多少字节;
- 能越界写什么样子的字节;
背景与动机
额外能力
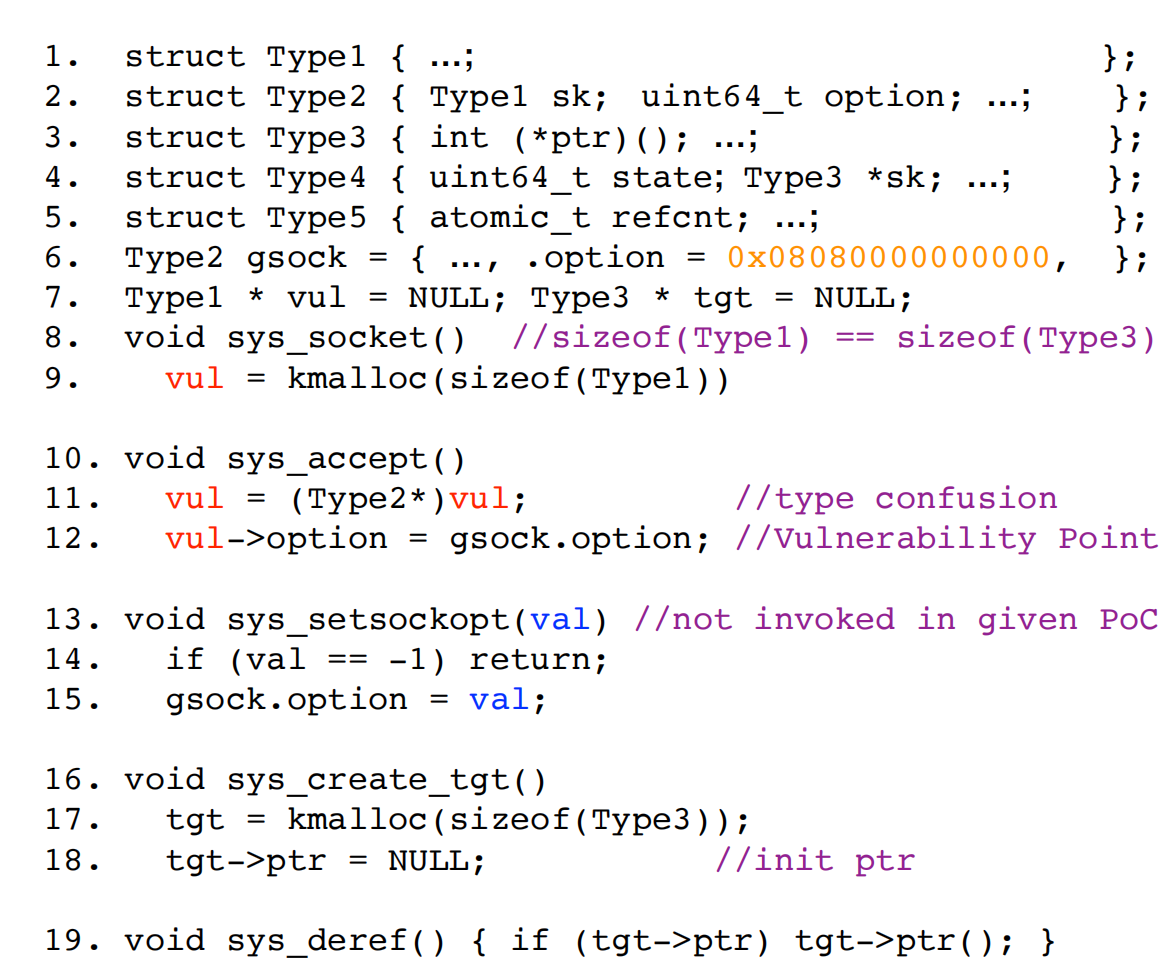
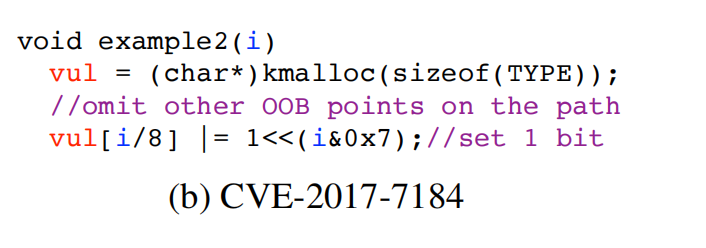
在代码的11行类型混淆,12行实现越界写,看起来是写固定值0x08080000000000,但是其实这个gsock->option的值是可以被系统调用sys_setsockopt来修改,但是原始的poc缺并没有发现这个;
:star::star:漏洞能力的建模+额外能力的发现
漏洞攻击步骤

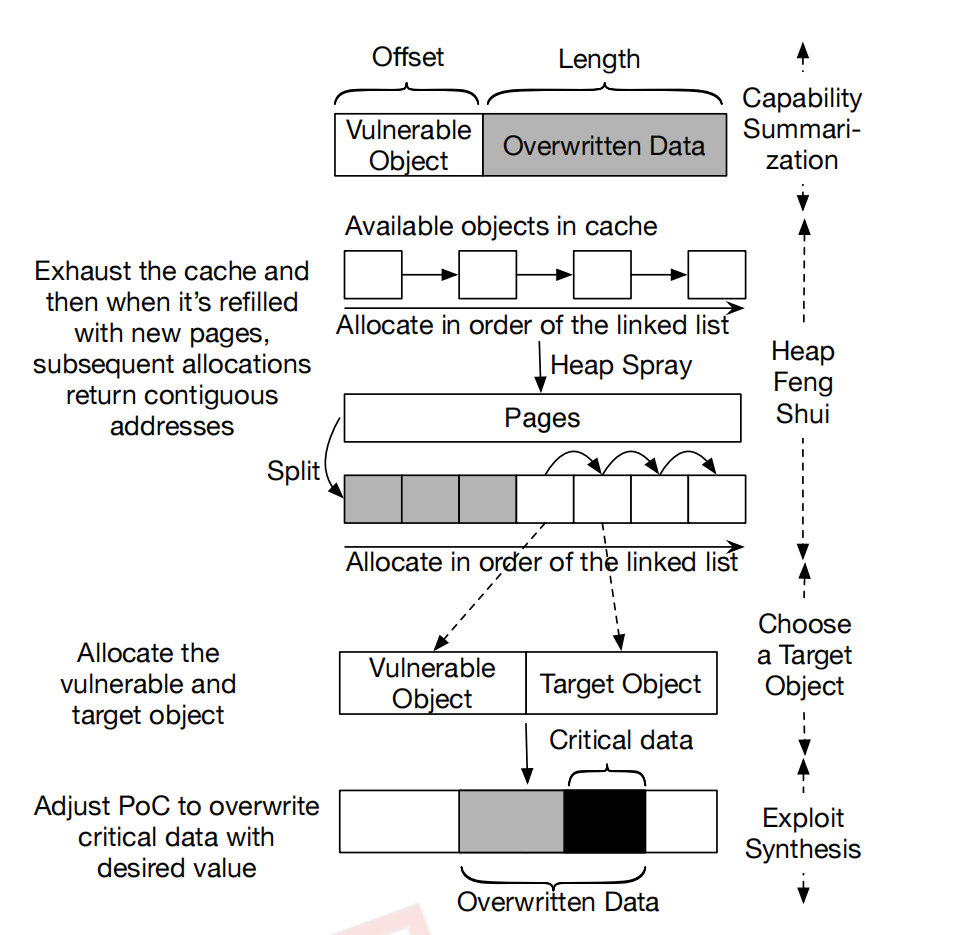
这个图就是展示了oob一个同kmem_cache的obj的过程;
功能提取
现在很多poc并不能直接到可利用状态,需要安全研究员去分析相应代码上下文、添加系统调用等;
堆风水
一个slab的obj耗尽以后会向buddy system申请新的物理页并切割,此时新的obj的分配往往是从低地址到高地址按顺序分配的,这样有利于溢出的顺利进行;(其实我觉得可以通过大量喷射来解决)
通用结构体的使用:msg_buf;
目标选择
目标结构的归类:
- 函数指针
- 数据指针
- 非指针(uid、refcount等也很重要)

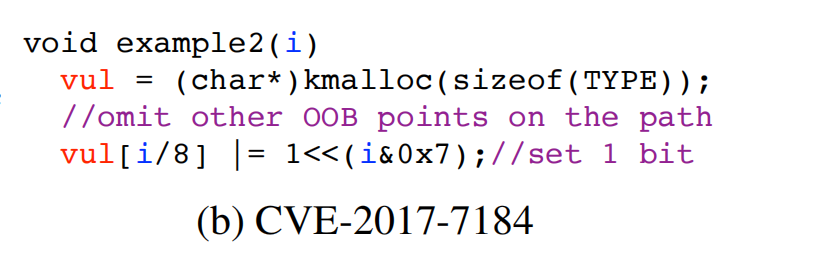
继续看这个图,Typee2中包含了一个Type1,所以类型混淆后写option其实就是越界后的前8个字节;
越界写的能力是有限制的,所以需要收集各类包含重要域的obj;
例如:CVE-2016-6187只能越界写一个字节的0,就只能攻击引用计数在首部的obj;
EXP的合成
绕过防御+劫持控制流
KASLR:独立的信息泄露漏洞、CPU侧信道攻击;
SMEP:ROP、JOP;
SMAP:ret2dir/内核线性映射区;
设计
首先进行能力提取,然后评估所有潜在的target object;
简化状态寻找的过程,值判断target object是否满足需求;(在已知的堆布局中)
模块化的工作不同于以往的工作(只考虑一次性输入的漏洞或者通过探索不同的UAF漏洞隐式地考虑能力;)
概述
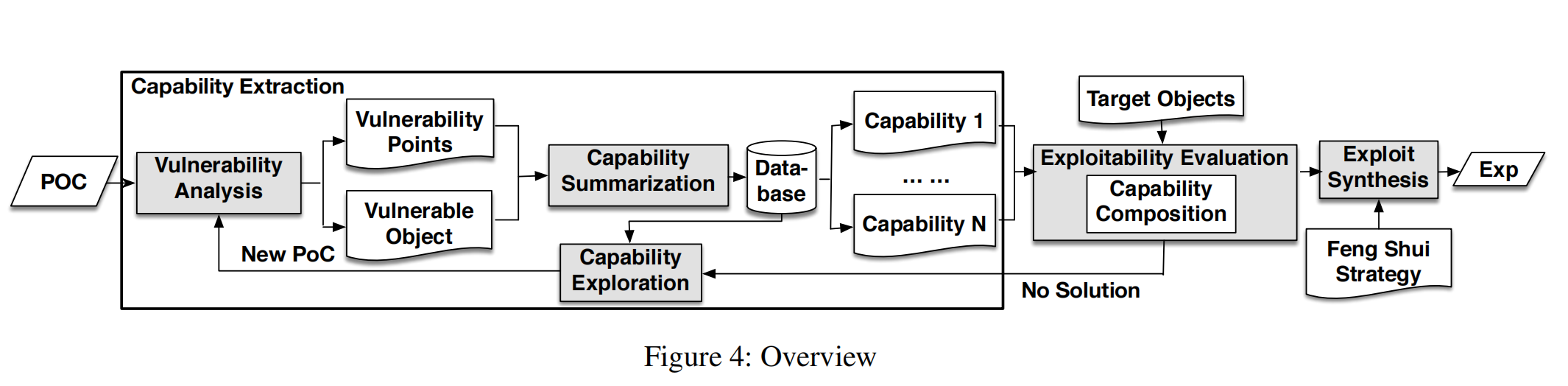
- 符号跟踪的poc去分析一个poc的能力;
- 通过使用一个或者多个target obj来判断是否可利用;
- 如果没有发现合适的,就触发能力发现的其他步骤去发现新的能力;(这种情况下,如果一个漏洞允许反复触发OOb write去写同一个vulnerable object,它结合了来自不同攻击路径的不同能力)
- 如果发现了合适的target object,就合成exp;
4.1 漏洞分析
给定一个poc,首先尝试发现所有的漏洞点,并且识别对应的vulnerable object;
KASAN:
基于影子内存和红区
影子内存:


参考:https://blog.csdn.net/feelabclihu/article/details/109685476
建立影子内存,记录可访问的长度,编译内核时插桩,判断是否为非法访问:


符号跟踪
==构建符号跟踪来辅助KASAN==
监控更加细粒度的内存操作:例如kmalloc,当每一个object被分配的时候,就创建一个独一无二的符号值,因此对于每次内存访问如果它包含一个符号表达式,我们可以直接提取目标对象;(通过查询指针的符号表达式的可能范围,还能探测到潜在的溢出漏洞)
例如,Line9分配的到一个obj,在Line12得到如下表达式:
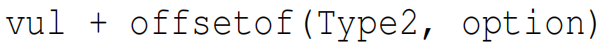
其中vul是我们分配的符号值;
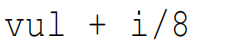
4.2 能力总结
定义一:OOB write set:
E 表示符号执行引擎所支持的所有符号表达式的集合;
P 表示所有路径的集合;
$N_p$ 每一个漏洞点的路径p$\in$P,它们的集合即为$N_p$;
==$T_p$ 对应OOB write 漏洞的集合,$T_p = {(off_{pi}, len_{pi}, val_{pi}) | i \in N_p \and off, len, val \in E }$==
这里的 i 属于每一个漏洞点的路径,然后off、len、val都能被 E 表示,然后 $Tp$ 则是每一个漏洞点,用off、len、val三个关键参数描述;off是越界写的偏移,len是写的长度,val是写的值;因此,OOb write在 $T_p$ 的第 i 个漏洞点表示为 $T_{pi}$
要注意OOB write写入的顺序,后边的更重要,因为会有覆盖;循环;
总结:一个漏洞(代码写的不好)可能导致多个不同的漏洞点(后续执行到了越界写的位置),然后每一个漏洞点可能是不同的情况(这可能就取决于攻击者的参数了),所以这里的$T_p$就是针对一个漏洞的所有漏洞点而言的,那么就是多种情况的集合了;
定义二:Capability:
==$C_p = {size_p, T_p, f(p) | size_p \in E}$==
$size_p$代表vulnerable object的size,f(p)代表执行到路径p时收集到的路径约束;
obj的可变size也被我们视为是一种能力;
符号公式 + size + 路径约束 功能组成我们的能力;
定义三:Capability Comparision

任意e1 e2两个属于E的符号表达式,e1小于等于e2的定义是:e1等价于e2或者e1是一个常量,它的值可以被e2提取出来;
能力分类
将能力归为两类:函数调用和内存访问;
对memcpy等函数的建模可以简化能力的提取;
4.3 能力探索
一个漏洞可能导致多个不同的利用路径,也就展现出了多种不同的能力;但是一个poc往往只能代表一个路径;
如果不能找到一个合适的目标结构体,就继续去发现新的poc或者能力;
能力引导的fuzz
给定一个poc和它的OOB write的能力,我们对它进行变异,并将收集到的能力和覆盖率一起反馈回去;最终将这些能力喂给符号跟踪引擎进行新的分析;新提取出来的C2,如果严格优于原来的能力C1,则C2被视为是新的能力;
特别地,当一个程序被执行的时候,我们收集OOB write能力的具体值作为反馈值;
在fuzz中使用轻量的动态指令收集OOB write的能力;妥协则是可能会重复;(例如,如果我们知道了OOB write的value可以是任意值,那么后续仅value不同的case都是多余的)缓解方法:建立集合,不仅仅比较值、海比较范围;
提高覆盖率比发现新的能力要容易很多,所以语料库中可能会大量保存提高覆盖率的test program,使用两个队列,分别给提高覆盖率和发现总结能力,然后以相同概率使用它们。
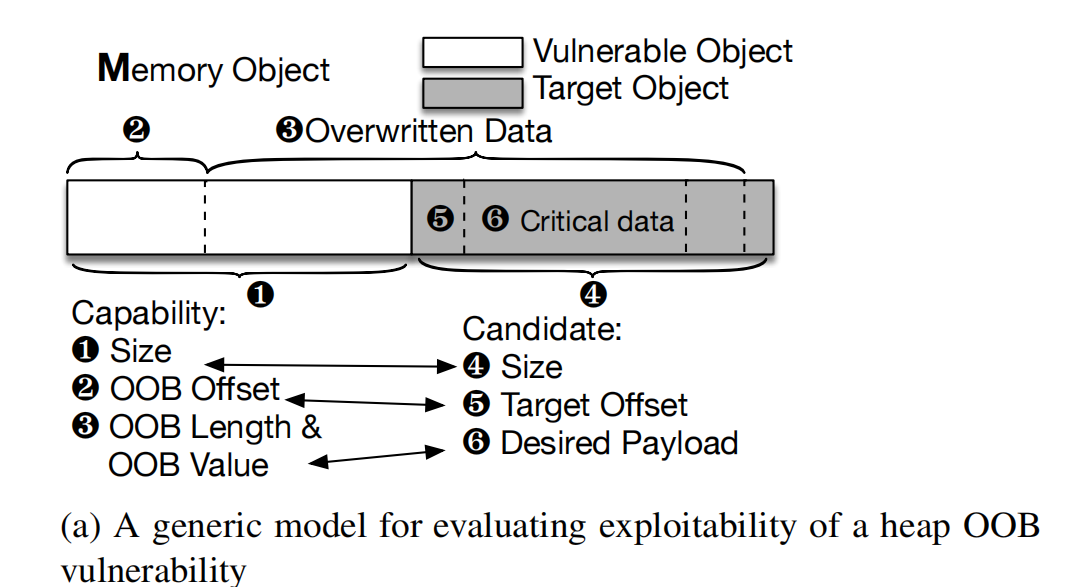
4.4 可利用性评估
目标约束:描述了一个目标结构体被利用的条件;
内存模型
构建了==内存模型M,==符号化的index、size、value;先通过能力初始化该内存模型的参数,然后通过将候选的目标对象的约束加进来,来判断是否符合;

对漏洞对象构建一个内存模型,然后尝试匹配候选目标对象;
首先候选对象的size必需和漏洞对象的size保持一致;
用offset、length、value等更新内存模型M;
最后约束求解;
能力组合
可能一次OOB write只能篡改一个bit,造成部分写,所以需要组合能力;
使用贪心算法进行组合评估:
为了使关键字段更接近目标值,设计了一个距离函数,在迭代中知道选择最近的capability;
每一个选择将其结果写回内存对象,以便下一次迭代可以继续减少距离;
下面是各类距离函数:

理解:本身应该是一个搜索问题,判断路径是否存在(组合各种capabilities);
4.5 EXP原语的合成
堆风水
使用add_key、msgsnd、send_msg等耗尽kmem_cache;
搜集exp总结使用、构建数据集:

这个的实现仅仅是劫持RIP、并没有完整的利用链;
总结
- 漏洞分析的亮点在于在KASAN的基础上提升,对于每次内存分配都给一个符号值,然后在内存访问的时候给出相应的符号表达式;
- 能力总结,则是定义了一些符号以及关系的比较;
- 能力探索,能力引导变异的fuzz,添加了一种反馈机制;
- 可利用性评估,构建了一种内存模型,给漏洞对象设计一个内存模型,然后尝试匹配候选目标对象;$\Rightarrow$ 能力组合:使用贪心算法,构造距离函数;
- EXP原语的合成;
具体实现
动态Instrumentation支持能力指导的fuzz
S2E:

使用S2E配合syzkaller,可以检查内核的内部状态,从而避免崩溃,提高fuzz的效率:
具体做法是让内核跳过那些导致panic的OOB write指令,避免任何KASAN的警告;但是会带类副作用:导致内核进入到错误的状态(或许这个状态根本就不对);
支持符号化的长度
符号化的length不好表示,相比于符号化的index和value;
给定一个漏洞OOB write(off, len, val) 此时我们指导这个漏洞操作的起始偏移、能写的长度以及能写的值的范围,具体的长度是10,
基于枚举的思想:
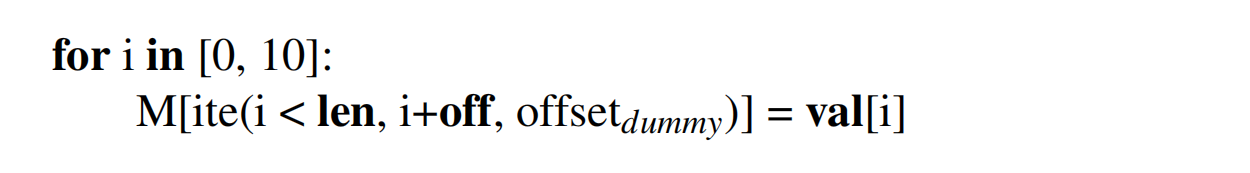
从前向后枚举,这里基于一个假设,前面的byte和后边的byte无关,
循环中的能力提取

越界写的字节数目受输入n的影响,但是常规的符号执行引擎中n的符号是不会传递到迭代变量 i 中,借鉴SAGE的思路,使用简单的循环保护&&模式匹配规则自动的推测循环中的迭代变量的表达式,(这里又给予一个简单的假设,迭代变量和边界变量是线性关系),因此只需要关注包含我们的漏洞点的特定的循环,使用Angr进行静态分析;
解决符号化索引和循环边界&&解决路径冲突
对于我们的漏洞点,可能开始总结出来的路径限制过于严格了,比如后来我们想少溢出一个字节,但是这不符合我们开始总结出来的路径限制,前人有类似工作,path kneading,用来识别一个路径暂时转移路径然后再合并到用一个关键点上,但是这个方法消耗太大了;
本论文的想法是,
我们的观察是,由于数组索引和循环边界的具体化而产生的这种过度约束可以通过简单地删除它们的约束来很容易地处理。
潜在的理由是,内存索引从运行到运行动态分配对象的地址不太可能保持不变,因此具体的符号索引在内存访问操作通过添加一个约束限制索引的索引禁止求解器改变索引和不必要的过度限制搜索空间。
在这个例子中,n 被输入为64,导致了65个限制条件:0<n,1<n,2<n,…,64>=0;这些限制是不必要的,所以直接删除,这就是个放松处理;
消除不必要的限制条件
有时候会收集到过于复杂的路径限制:一方面是类似于printk这种和我们的目标无关的限制可以直接去掉;另一方面是类似于条件竞争这类的输入,多次反复使用同样参数的syscall,导致了条件的积累,识别多个线程中重复的限制,然后只保留最后一个(触发OOB);通过注释提醒?
目标收集
target constrains是由关键字段的offset、size、type(什么结构体含有关键字段);
相关信息:如何分配、如何触发解引用;
使用LLVM pass构建整个kernel的调用图,依赖于它,我们可以找到相应的分配和解引用的点;
这是静态分析而来,调用图不是很精确,且没有具体的输入,因此只能用这个调用图排出来一个优先级;
此外,还从exp中收集常用结构体;
SLAKE:该工具使用fuzz自动且系统地生成分配和解引用的目标输入;



